



Table of Contents
show
In the digital age, where there is a wealth of information available on the internet, it can be a daunting task to manually gather and collect data from various websites. This is where web scraping comes in handy.
What is Web Scraping
Web scraping refers to the automated extraction of data from websites. With the help of specialized software, commonly known as web scrapers or web crawlers, businesses can collect data from various online sources and convert it into a structured format. Now, you might have understood what is web scraping solutions in detail.
Web scraping involves navigating through websites and extracting specific data points that are relevant to your business needs. By utilizing web scraping tools and services, businesses can automate the process of data collection and extraction, thereby saving time and resources.
Imagine you are running an e-commerce business and you want to keep track of your competitors’ prices. Instead of manually visiting each competitor’s website and noting down the prices, you can use a web scraper to extract the prices automatically. This not only saves you time but also ensures that you have accurate and up-to-date information. Web scraping solutions can be used for various purposes, such as market research, lead generation, sentiment analysis, and much more. The possibilities are endless. This is what is web scraping solutions.
Is Web Scraping Legal?
Although web scraping offers numerous advantages, it is crucial for businesses to understand and adhere to the legal and ethical guidelines surrounding its use. Ignorance or misuse of these guidelines may lead to legal repercussions or damage to a company’s reputation. Let’s explore the key considerations in detail. Well, what is web scraping and what are the legal things associated with are must to know.

Legal Considerations in Web Scraping
When engaging in web scraping solutions, it is crucial to comply with applicable laws, such as those governing intellectual property rights, website terms of service, and data protection regulations. Failure to do so can result in legal consequences that can range from warnings and fines to lawsuits.
Intellectual property rights protect the creations of the human mind, such as inventions, literary and artistic works, and symbols, names, and images used in commerce. Web scraping solutions must respect these rights by not infringing on copyrighted material or trademarks. It is essential to understand the scope of fair use and ensure that the scraped content does not violate any intellectual property laws.
Website terms of service are legal agreements between the website owner and its users. These terms often include provisions that explicitly prohibit web scraping or impose specific restrictions on its use. It is crucial to review the terms of service of each website before scraping it to ensure compliance. Violating these terms can result in legal action, including cease and desist letters or even lawsuits for breach of contract.
Data protection regulations, such as the General Data Protection Regulation (GDPR) in the European Union, govern the collection and processing of personal data. Web scraping activities must respect these regulations by obtaining necessary consent from users before collecting their personal information. Additionally, businesses must handle and store the scraped data securely to prevent unauthorized access or data breaches.
Ethical Guidelines for Web Scraping
Ethics play a vital role in web scraping. Businesses should ensure that they respect the rights of website owners and prioritize user privacy. It is crucial to seek consent, when required, and avoid scraping sensitive or copyrighted information.
Transparency and accountability should be the guiding principles when utilizing web scraping for business purposes. Clearly communicating the purpose of the scraping activity and providing users with the option to opt-out can help build trust and maintain ethical standards. Additionally, businesses should implement measures to protect the scraped data and prevent its misuse or unauthorized access.
Furthermore, businesses should consider the impact of web scraping on the website’s performance. Excessive scraping can put a strain on the server and negatively affect the user experience for other visitors. Implementing scraping techniques that minimize the impact on the website’s performance, such as using appropriate scraping intervals and respecting robots.txt files, is essential to maintain ethical practices.
By adhering to legal requirements and ethical guidelines, businesses can ensure that their web scraping activities are conducted responsibly and without causing harm to others. It is always advisable to consult legal professionals to ensure compliance with the specific laws and regulations applicable to the jurisdiction in which the scraping is taking place. What is web scraping is now clear, let us learn how web scrapers work.
How Does a Web Scraper Work?
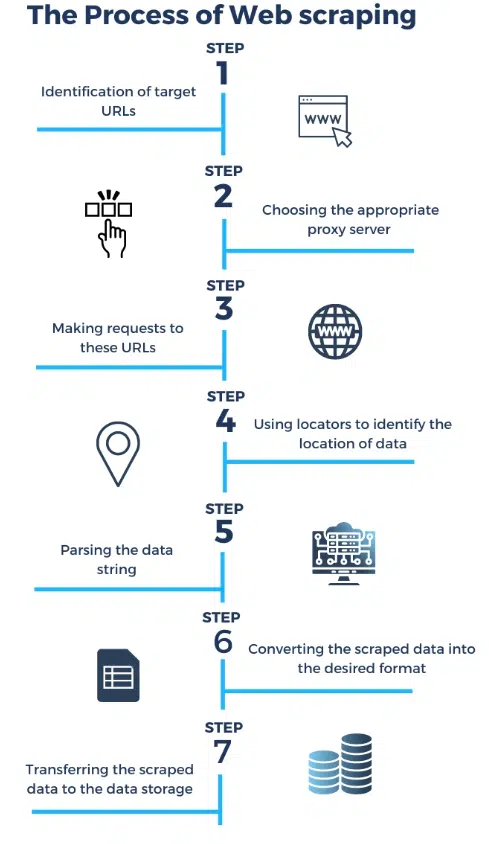
Source: https://research.aimultiple.co
Web scraping follows a structured process. The first step involves sending a request to a target website’s server. This request is similar to the one your browser sends when you visit a website. The server then responds to the request by sending back the HTML code of the webpage.
Once the web scraper receives the HTML code, it starts parsing it to extract the desired data. Parsing involves analyzing the structure of the HTML code and identifying the specific elements that contain the data you are interested in. This could be anything from product prices to customer reviews.
After extracting the data, the web scraper can store it in a structured format, such as a spreadsheet or a database. This allows businesses to easily access and analyze the collected data.
Web scraping can be a complex process, especially when dealing with websites that have dynamic content or require authentication. However, with the right web scraping tools and service, businesses can overcome these challenges and harness the power of web scraping services to gain valuable insights and stay ahead of the competition.
Types of Web Scrapers
Web scrapers are software tools designed to extract data from websites. They come in various types and can be categorized based on their functionality, purpose, and how they access and parse web content. Here are some different types of web scrapers:
Basic Scrapers:
- HTML Scrapers: These scrape data from HTML pages by parsing the markup. They can extract text, links, and other elements from web pages.
- Text Scrapers: These focus on extracting text content from web pages, such as articles, blog posts, or news articles.
Advanced Scrapers:
- Dynamic Content Scrapers: These can scrape websites with JavaScript-driven content. They use headless browsers or automation tools like Selenium to interact with web pages and extract data.
- API Scrapers: These interact directly with web APIs to retrieve structured data. Many websites offer APIs for accessing their data in a structured format.
Specific-Purpose Scrapers:
- E-commerce Scrapers: Designed to extract product information, prices, and reviews from e-commerce websites.
- Social Media Scrapers: These scrape data from social media platforms like Twitter, Facebook, or Instagram, including posts, comments, and user profiles.
- News Scrapers: Focused on extracting news articles, headlines, and related information from news websites.
- Job Scrapers: Collect job listings and related data from job search websites.
- Real Estate Scrapers: Extract property listings, prices, and details from real estate websites.
Image and Media Scrapers:
- Image Scrapers: Download images from websites, often used for image datasets or stock photo collections.
- Video Scrapers: Collect video content and metadata from websites like YouTube or Vimeo.
Monitoring and Alert Scrapers:
- Change Detection Scrapers: Continuously monitor websites for changes and notify users when specific criteria are met (e.g., price drops, content updates).
Custom-Built Scrapers:
- Tailored scrapers developed for specific, unique use cases. These are often created by web scraping service providers to meet specific data extraction requirements.
Automated Web Scraping Solutions:
In the digital age, data is the new currency. Whether you’re a business looking for market insights, a researcher in need of datasets, or simply a curious individual, web scraping has become an indispensable technique for extracting valuable information from the vast expanse of the internet. Automated web scraping, in particular, has revolutionized the way we gather data, making the process more efficient and scalable.
Automated web scraping involves using software to navigate websites, extract specific information, and store it in a structured format. Here’s why it’s such a game-changer:
- Efficiency: Manual web scraping is time-consuming and error-prone. Automation allows you to gather data at a much faster pace, saving you countless hours of manual work. You can set up automated scripts to scrape data from multiple sources simultaneously, increasing your productivity exponentially.
- Consistency: Automated web scraping solutions ensures consistency in data extraction. Human errors, such as typos or omissions, are eliminated, resulting in more accurate and reliable datasets.
- Scalability: With automation, you can easily scale your web scraping operations. Whether you need to collect data from a handful of websites or thousands, automation can handle the task effortlessly.
- Timeliness: Many websites regularly update their content. Automated scraping enables you to stay up-to-date with the latest information, providing you with a competitive advantage in various fields, such as e-commerce, finance, and news aggregation.
- Customization: Automated web scraping can be tailored to your specific needs. You can extract data from websites, APIs, or databases, and customize your scripts to filter and format the information as required.
- Cost-Effective: While setting up automated web scraping initially requires some technical expertise, it ultimately saves money by reducing labor costs and minimizing human errors.
However, it’s essential to approach web scraping ethically and legally. Always respect a website’s terms of service, robots.txt file, and copyright laws. Additionally, be mindful of the impact your scraping may have on the target website’s performance. Automated web scraping is a powerful tool that streamlines the process of data extraction from the web. Its efficiency, scalability, and customization options make it indispensable for businesses, researchers, and individuals seeking valuable insights and information in the digital age. When used responsibly, automated web scraping can unlock a world of data-driven opportunities.
Python: The Ultimate Tool for Web Scraping
Python has emerged as the go-to language for web scraping, and it’s not by chance. Its popularity in this domain is underpinned by several compelling reasons.
Versatility and Ease of Learning
Python’s simplicity and readability make it an ideal choice for web scraping, regardless of your programming experience. Its code is akin to plain English, making it accessible to beginners and seasoned developers alike.
Rich Ecosystem of Libraries
Python boasts a treasure trove of libraries designed explicitly for web scraping. Among them, BeautifulSoup and Scrapy stand out. These libraries abstract complex tasks, such as parsing HTML and making HTTP requests, streamlining the scraping process significantly.
Active Community Support
Python is backed by a vibrant and enthusiastic developer community. Countless online resources, tutorials, and forums are available to assist with web scraping challenges, ensuring that you’re never stuck without guidance.
Cross-Platform Compatibility
Python runs seamlessly on various operating systems, from Windows to macOS and Linux. This cross-platform compatibility means that your web scraping scripts can operate consistently across different environments.
Robust Data Parsing
With its string manipulation capabilities, Python excels at navigating and extracting data from web pages, even when dealing with intricate page structures. BeautifulSoup, in particular, simplifies the parsing of HTML and XML documents.
HTTP Request Handling
Python’s ‘requests’ library streamlines the process of making HTTP requests, which is fundamental to web scraping. It handles common tasks like GET and POST requests, cookie management, and redirects, making your scraping endeavors hassle-free. Python web scraping is widely used these days.
Integration with Automation Tools
For websites with dynamic content, Python plays well with automation tools like Selenium. This allows you to interact with pages just as a human user would, ensuring access to content that requires user interaction.
Data Processing and Analysis
Python’s data processing and analysis libraries, such as Pandas and NumPy, facilitate cleaning, transforming, and analyzing the data extracted during web scraping. This means you can turn raw data into actionable insights.
Ethical Scraping Practices
Python’s flexibility enables the implementation of ethical scraping practices. You can respect website terms of service, adhere to robots.txt guidelines, and manage request rates to minimize the risk of IP blocking.
Integration with Databases and APIs
Python’s versatility extends to its capability to connect with various databases and web APIs. This allows you to store and retrieve scraped data for further analysis or integration into your applications.
Business Benefits of Web Scraping
Web scraping offers numerous benefits that can significantly impact businesses across various industries. Let’s explore some key areas where web scraping can prove invaluable.
Enhancing Market Research – Market research forms the foundation of any successful business. With web scraping, businesses can gather a wealth of information about their competitors, market trends, pricing strategies, and customer preferences. By analyzing this data, businesses can make more informed decisions and devise effective strategies to stay ahead of the competition.
For example, web scraping can help businesses track their competitors’ pricing strategies in real-time. By monitoring the prices of similar products or services, businesses can adjust their own pricing strategies to remain competitive. Additionally, web scraping can provide insights into customer sentiment by analyzing online reviews and social media posts. This information can help businesses understand customer preferences and tailor their products or services accordingly.
Boosting Lead Generation – Generating quality leads is crucial for business growth. Web scraping enables businesses to extract contact information, such as email addresses and phone numbers, from websites and directories. This data can then be used for targeted marketing campaigns, increasing the chances of reaching potential customers and generating leads.
Furthermore, web scraping can help businesses identify potential leads by monitoring online forums, social media platforms, and industry-specific websites. By analyzing discussions and interactions, businesses can identify individuals or organizations that express a need or interest in their products or services. This proactive approach to lead generation can significantly improve conversion rates and drive business growth.
Streamlining Data Collection – Data is integral to decision-making, and web scraping simplifies the process of data collection. Instead of manually visiting multiple websites and copying information, businesses can automate the data extraction process. Web scraping enables businesses to gather large volumes of data quickly and efficiently, allowing for more accurate analysis and faster insights.
For instance, web scraping can be used to collect data from e-commerce websites to analyze product trends, customer behavior, and pricing patterns. This information can help businesses optimize their product offerings, improve customer satisfaction, and identify new market opportunities. Additionally, web scraping can be utilized to gather data from news websites, blogs, and industry publications, providing businesses with up-to-date information on industry developments and trends.
Web scraping services play a crucial role in enhancing market research, boosting lead generation, and streamlining data collection for businesses. By harnessing the power of web scraping, businesses can gain a competitive edge, make informed decisions, and drive growth in today’s digital landscape.
How to Web Scrape
Let’s delve into some key aspects to consider when incorporating web scraping into your operations.
Choosing the Best Web Scraping Tools
When it comes to web scraping, you have two main options: using web scraping tools or outsourcing the task to web scraping service providers. Let’s start by exploring the different aspects of web scraping tools:
There are a wide range of web scraping tools available in the market. It is essential to evaluate your business needs and select a tool that offers the required features, scalability, and ease of use. Conduct thorough research and consider factors such as data extraction capabilities, customization options, and customer support before making a decision. Some factors to consider are:
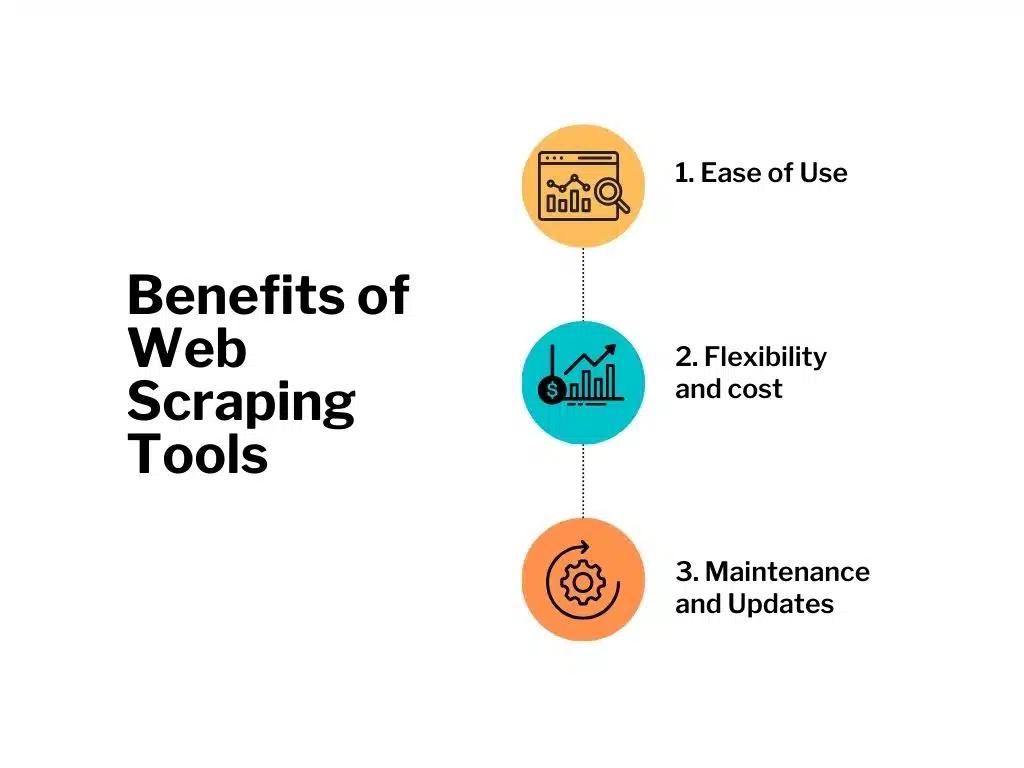
- Ease of Use: Web scraping tools come with user-friendly interfaces and require minimal coding knowledge. They offer a visual scraping feature that allows you to select the data you need from a website easily. Some popular web scraping tools include Beautiful Soup, Scrapy, and Octoparse.
- Flexibility: With web scraping tools, you can customize your scraping scripts according to your specific requirements. They provide the flexibility to scrape data from multiple websites simultaneously, handle complex web pages, and extract data in various formats like CSV, JSON, or XML.
- Cost: Web scraping tools are generally more cost-effective compared to outsourcing the task to service providers. Most tools offer free versions with limited features, while paid versions provide advanced functionalities and support.
- Maintenance and Updates: As technology evolves, websites often change their structure, making it necessary to update scraping scripts. Web scraping tools require regular maintenance and updates to ensure accurate and continuous data extraction.
Evaluating Web Scraping Service Providers
While web scraping tools can be an excellent choice for individuals or small-scale projects, they may not always be the best solution for businesses with complex scraping needs. To make an informed decision, consider the following factors when evaluating web scraping service providers:
- Scalability: Service providers have the infrastructure and resources to handle large-scale web scraping projects efficiently. They can handle concurrent scrapes, provide access to multiple proxy servers to bypass website restrictions, and ensure uninterrupted data extraction.
- Data Quality: Web scraping service providers specialize in delivering high-quality and accurate data. They can navigate challenges such as CAPTCHA, dynamic websites, and changing page structures more effectively, resulting in reliable and consistent data.
- Legal Compliance: Web scraping can be a legal gray area, and service providers are well-versed in navigating the legal complexities. They ensure compliance with website terms of service, copyright laws, and data protection regulations, reducing the risk of legal consequences.
- Customization and Support: Service providers offer tailored solutions to meet your specific scraping requirements. They can handle complex data extraction tasks, provide custom data formatting, and offer ongoing technical support.
Why Choose Web Scraping Service Providers Over Tools
While web scraping tools have their merits, there are compelling reasons why businesses should consider outsourcing web scraping to service providers:
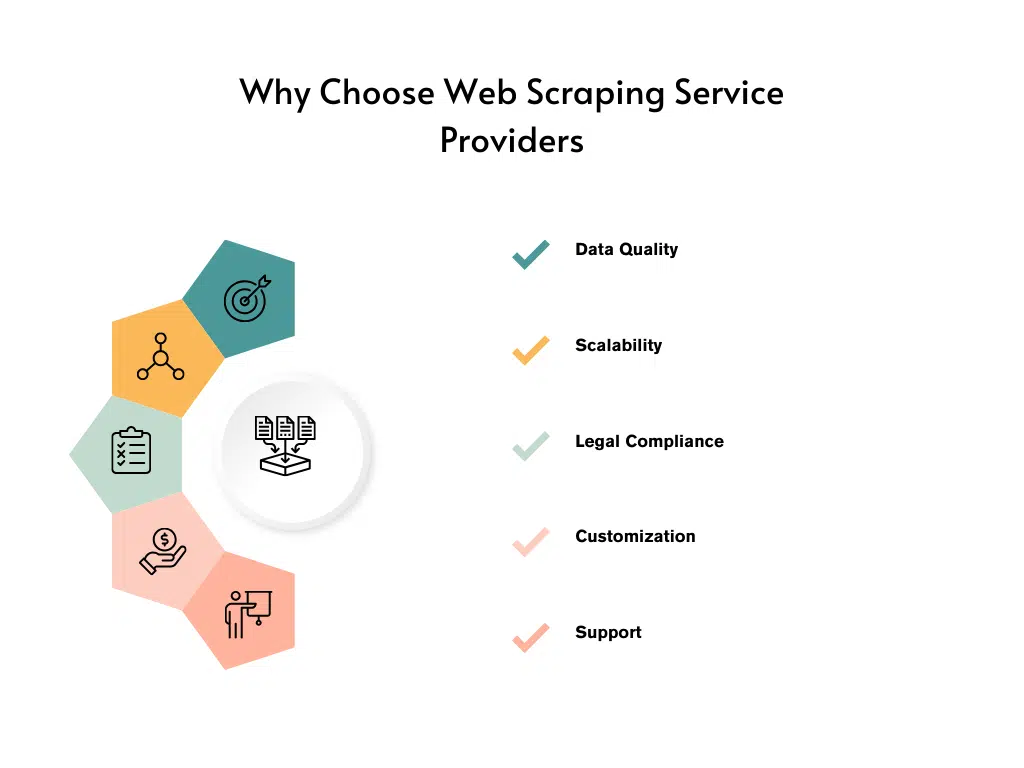
- Expertise and Experience: Web scraping service providers specialize in data extraction and have extensive experience in handling a wide range of scraping projects. They possess the necessary expertise to overcome challenges and deliver reliable results.
- Focus on Core Competencies: Outsourcing scraping allows businesses to focus on their core competencies instead of investing time and resources in mastering scraping tools and techniques. This enables companies to prioritize their key activities and drive growth.
- Cost-Effective: Contrary to popular belief, web scraping service providers can often offer cost savings in the long run. They can deliver accurate and relevant data faster, allowing businesses to make data-driven decisions promptly, resulting in improved operational efficiency.
- Saves Time and Effort: Web scraping service providers take care of the entire web scraping process, from data extraction to handling maintenance and updates. This frees up your team’s time and effort, allowing them to concentrate on analyzing the extracted data and deriving valuable insights.
Web scraping is a valuable tool for businesses seeking to harness the power of data. While web scraping tools can be useful for small-scale projects, outsourcing to web scraping service providers offers numerous advantages, including scalability, data quality, legal compliance, customization, and professional support. By carefully evaluating your requirements and considering these factors, you can make an informed decision that best suits your business needs.
Web Scraping Best Practices: Harnessing Data Responsibly and Effectively
Scraping is a valuable technique for extracting data from websites, enabling businesses, researchers, and developers to gather insights and automate tasks. However, it’s essential to learn how to web scrape and approach web scraping with responsibility and respect for legal and ethical considerations. In this article, we’ll explore some best practices for web scraping to ensure you harness data effectively and ethically.
- Respect Website Terms of Service: Before scraping any website, review its terms of service and scraping policy. Some websites explicitly prohibit scraping or may impose limitations. Compliance with these terms is crucial to maintain a positive relationship with the website owners and avoid potential legal issues.
- Check for a “robots.txt” File: The “robots.txt” file is a standard used by websites to communicate with web crawlers and scrapers. It specifies which parts of the website are off-limits to scraping. Always check for this file and adhere to its directives to avoid unwanted consequences.
- Use Scraping Libraries and Tools: Utilize reputable web scraping libraries and tools like BeautifulSoup (Python), Scrapy, or Puppeteer (JavaScript). These frameworks offer structured ways to interact with websites, making your scraping process more efficient and maintainable.
- Set Appropriate Rate Limits: Avoid overloading a website’s server with too many requests in a short period. Implement rate-limiting to prevent server overload and reduce the risk of getting blocked by the website. Respect the website’s bandwidth and responsiveness.
- Handle Errors Gracefully: Websites may change their structure or experience temporary downtime. Your scraping code should handle these situations gracefully, logging errors and retrying requests when necessary. This ensures the reliability of your scraping process.
- Avoid Scraping Personal or Sensitive Information: Never scrape personal or sensitive data, such as email addresses, phone numbers, or private user information, without explicit consent. Focus on public data and information that is legally accessible.
- Identify Yourself: Make it clear who you are when sending requests to websites. Set a user-agent header that identifies your scraping bot or script. This transparency can help website administrators distinguish legitimate scrapers from malicious ones.
- Use Proxies and Rotate IP Addresses: To prevent IP bans or rate-limiting, consider using proxy servers and regularly rotating IP addresses. This practice helps distribute requests across different IPs, reducing the risk of detection or blocking.
- Respect Copyright and Intellectual Property: Be cautious when scraping content subject to copyright or intellectual property laws. While you can extract factual information, avoid reproducing copyrighted content verbatim or without proper attribution.
- Test Locally and Monitor Performance: Before deploying a web scraping script at scale, test it locally and monitor its performance. This allows you to fine-tune your code, identify potential issues, and ensure that your scraping process is efficient and reliable.
- Stay Informed of Legal Regulations: Familiarize yourself with the legal regulations and privacy laws relevant to scraping in your region and the region of the website you’re scraping. Compliance with data protection laws, such as GDPR or CCPA, is essential when dealing with user data.
- Be Polite and Ethical: Maintain a respectful and ethical approach to web scraping. Avoid aggressive scraping tactics, such as bypassing CAPTCHAs or attempting to overload a website’s server. Ethical scraping promotes a positive image of data professionals and developers.
Web scraping is a powerful tool for data extraction, but it comes with responsibilities. Following these best practices ensures that you harness data effectively, respect the rights of website owners, and operate within legal and ethical boundaries. By doing so, you can unlock the full potential of scraping while maintaining a positive online presence and reputation.
Frequently Asked Questions
What does scraping a website do?
Scraping a website involves programmatically accessing a website and extracting data from it. This process is typically performed by a software tool or script that sends requests to the website, retrieves the web pages, and then parses the HTML of those pages to extract specific information. The extracted data can then be saved into a structured format, such as a CSV file, a database, or a JSON file, for further use or analysis. Here’s what scraping a website accomplishes:
Data Extraction
The primary purpose of web scraping is to extract data. This could include product details from e-commerce sites, stock prices from financial websites, job listings from employment portals, or any other information that is publicly accessible via the web.
Data Aggregation
Web scraping allows for the aggregation of data from multiple sources. This is particularly useful for comparison sites, market research, and content aggregation platforms that need to gather and present data from various websites in a unified manner.
Automation of Data Collection
Scraping automates the otherwise manual and time-consuming task of data collection. Instead of copying and pasting information from websites, a scraper can automatically collect vast amounts of data in a fraction of the time.
Content Monitoring
Scraping can be used for monitoring changes to website content. This is useful for tracking price changes, product availability, new job postings, or updates to news stories and articles.
SEO and Market Analysis
Businesses use web scraping to analyze market trends, monitor competitor websites, and perform SEO analysis. This helps in understanding market positions, optimizing content for search engines, and strategic planning.
Machine Learning and Data Analysis
The data collected via web scraping can serve as input for machine learning models and data analysis projects. It provides the raw material for training algorithms, conducting sentiment analysis, trend forecasting, and more.
Improving User Experience
By scraping data such as user reviews and feedback from various sources, companies can gain insights into customer satisfaction and product performance, informing product improvements and enhancing user experience.
Is web scraping Zillow illegal?
The legality of web scraping, including sites like Zillow, depends on various factors, including how to web scrape, what data is scraped, and how that data is used. Additionally, the legal landscape regarding scraping is complex and can vary by jurisdiction. Here are some key points to consider when evaluating the legality of scraping data from websites like Zillow:
Terms of Service (ToS)
Websites typically have Terms of Service (ToS) that specify conditions under which the site may be accessed and used. Some ToS may explicitly restrict or prohibit the use of automated crawlers or scrapers without permission. Violating these terms could potentially lead to legal actions or being banned from the site.
Copyright Laws
Data collected through scraping might be protected by copyright. While factual data like prices or square footage may not be copyrighted, the collective work or the specific presentation of data on a website could be. Using such content without permission could constitute copyright infringement.
Computer Fraud and Abuse Act (CFAA)
In the United States, the CFAA makes unauthorized access to computer systems a criminal offense. Some legal interpretations have considered scraping in violation of a site’s terms of service as “unauthorized access,” though this is a contentious and evolving area of law.
Data Protection and Privacy Laws
Laws such as the General Data Protection Regulation (GDPR) in the European Union and similar regulations worldwide impose strict rules on how to web scrape, how personal data can be collected, used, and stored. Scraping personal information without proper consent or legal basis could be violating these laws.
Given these considerations, it’s essential to proceed with caution and seek legal advice before crunching data from websites like Zillow. In some cases, websites offer APIs or other legal means to access their data, which can be a safer and more reliable approach than scraping.
Is web scraping a good idea?
Scraping can be a powerful tool for businesses, researchers, and developers, offering numerous benefits when used correctly and ethically. However, whether it’s a good idea depends on the purpose, methods, legal considerations, and ethical implications involved. Here are some factors to consider:
Advantages of scraping
Efficient Data Collection
Web scraping automates the process of collecting large amounts of data from websites, which can significantly save time and resources compared to manual data collection.
Market and Competitive Analysis
Businesses can use scraping to monitor competitors, track market trends, and gather insights that inform strategic decisions, helping them stay competitive.
Data for Machine Learning Models
Scraping provides access to vast datasets needed for training and refining machine learning models, especially when such data is not readily available through other means.
SEO and Digital Marketing
Scraping helps in analyzing market presence, understanding SEO strategies of competitors, and improving content marketing strategies.
Real-time Data Access
For industries where real-time data is crucial, like stock markets or price comparison for e-commerce, scraping can provide up-to-the-minute data.
Can websites detect web scraping?
Yes, websites can detect web scraping through various means, and many implement measures to identify and block scraping activities. Here are some common ways websites detect scraping and some strategies they might use to prevent it:
Unusual Access Patterns
Websites can monitor access patterns and detect non-human behavior, such as:
- High frequency of page requests from a single IP address in a short period.
- Rapid navigation through pages that is faster than humanly possible.
- Accessing many pages or data points in an order that doesn’t follow normal user browsing patterns.
Headers Analysis
Websites analyze the HTTP request headers sent by clients. Scrapers that don’t properly mimic the headers of a regular web browser (including User-Agent, Referer, and others) can be flagged.
Behavioral Analysis
Some sites implement more sophisticated behavioral analysis, such as:
- Tracking mouse movements and clicks to distinguish between human users and bots.
- Analyzing typing patterns in form submissions.
- Using CAPTCHAs to challenge suspected bots.
Rate Limiting and Throttling
Websites might limit the number of requests an IP can make in a given timeframe. Exceeding this limit can lead to temporary or permanent IP bans.
Analyzing Traffic Sources
Sites may scrutinize the referrer field in the HTTP headers to check if the traffic is coming from expected sources or directly to pages in a way that typical users would not.
Integrity Checks
Some websites use honeypots, which are links or data fields invisible to regular users but detectable by scrapers. Interaction with these elements can indicate automated scraping.
Challenges and Tests
Implementing tests, such as CAPTCHAs or requiring JavaScript execution for accessing site content, can effectively distinguish bots from humans, as many simpler scraping tools cannot execute JavaScript or solve CAPTCHAs.















