


What is Web Crawling?
Web Crawling, also called Spidering, is the process of finding web pages and downloading them. While a Web Crawler, also known as Spider or a Robot, is a program that downloads web pages associated with the given URLs, extracts the hyperlinks contained in them and downloads the web pages continuously that are found by these hyperlinks. In a given period of time, a substantial fraction of the “surface web” is crawled. The web crawlers should be able to download thousands of pages per second, which in turn is distributed among hundreds of computers.
Companies like Google, Facebook, LinkedIn use web crawling to collect data because most of the data that these companies need are in the form of a web page with no API access. Data mining services help in crawling the web to a great extent.
Features of Crawler
- Politeness: Keep track of the maximum number of visits to the websites.
- Robustness: It should take care that it does not get trapped in the infinite number of pages.
- Distributed: The downloaded pages should be distributed among hundreds of computers infraction of seconds.
- Scalability
- Performance and efficiency
- Quality: It is important to maintain the quality of the hyperlinks downloaded
- Freshness
- Extensibility
Politeness Policy
A web crawler uses a small portion of the bandwidth of a website server, i.e. it extracts one page at a time. In order to implement it, the request queue should be split into a single queue per web server–a server queue is open only if it has not been accessed within the specified politeness window.
For example: if a web crawler can fetch 100 pages per second, and the politeness policy dictates that it cannot fetch more than 1 page every 30 seconds from a server–we need URLs from at least 3,000 different servers to make the crawler reach its peak throughput.
What are the different types of web crawlers?
- General-purpose web crawlers: These crawlers are designed to browse the entire web and collect information about all types of websites. They are typically used by search engines like Google, Yahoo, and Bing to index web pages for their search results.
- Focused web crawlers: These crawlers are designed to collect information from a specific set of websites or web pages. They are often used for research purposes, such as collecting data for academic studies or market research.
- Incremental web crawlers: These crawlers are designed to revisit websites at regular intervals and update their database with any new or updated content. They are commonly used by search engines and other web services to keep their databases up-to-date.
- Distributed web crawlers: These crawlers use a distributed network of computers to crawl the web. They are designed to handle large-scale crawls and can collect data from millions of web pages in a short amount of time.
- Focused crawler: These crawlers are specialized to crawl only specific types of web pages, like news sites or blogs, to collect content relevant to a specific topic.
- Vertical search engine crawlers: These crawlers are designed to crawl websites within a specific industry or niche, such as job search engines, real estate websites, hotel or travel booking websites.
Some of the other types of web crawlers include:
- Link validation crawlers
- Social media crawlers
- Image and video crawlers
- Malware crawlers, etc.
Each type of web crawler has its own specific purpose and can be used for a variety of applications.
How does a web crawler work?
A web crawler works by systematically browsing the internet to collect information from websites. Here’s a general overview of how a web crawler works:
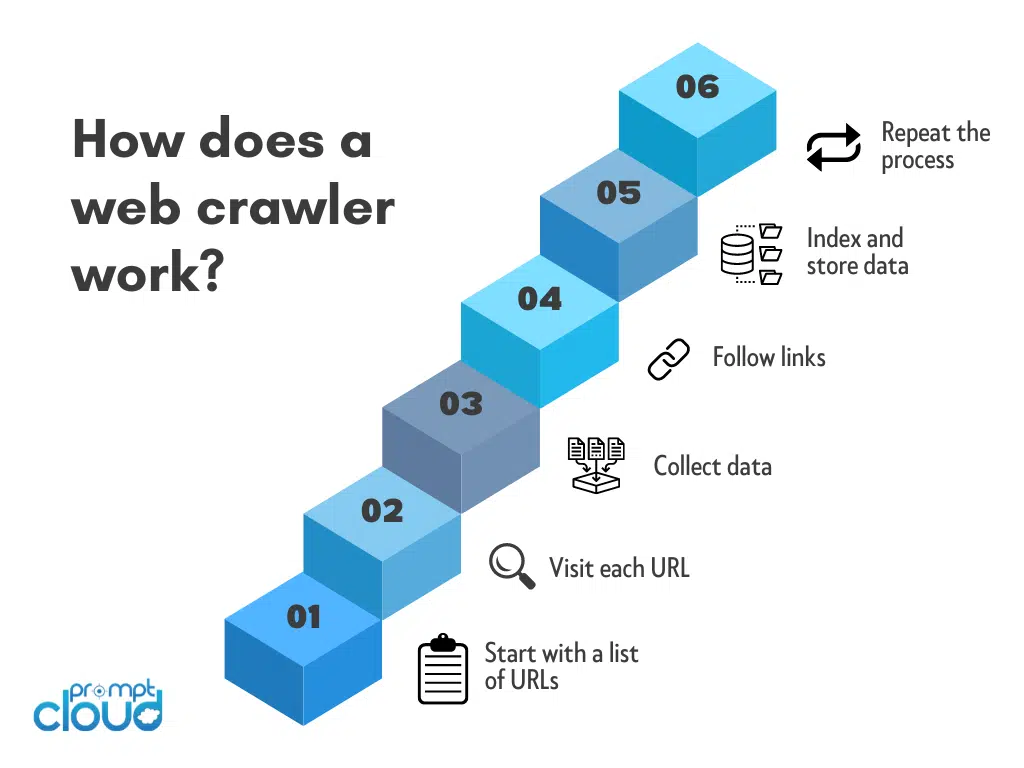
- Start with a list of URLs: The web crawler starts with a list of URLs to visit. This list can be generated in a number of ways, such as by using a search engine, following links from other websites, or by being provided a specific set of URLs to crawl.
- Visit each URL: The web crawler then begins to visit each URL on the list. It does this by sending an HTTP request to the server that hosts the website.
- Collect data: Once the web crawler has accessed a website, it collects data from the HTML code and other resources such as CSS, JavaScript, images, and videos. The data collected can include text, images, links, metadata, and other information about the web page.
- Follow links: The web crawler follows the links found on the web page to discover new pages to crawl. It repeats this process for each new page it finds until it has visited all the pages in the original list, or until it reaches a specified depth or limit.
- Index and store data: As the web crawler collects data, it indexes and stores it in a database or index. This makes it possible for the information to be retrieved and used for various purposes, such as search engine indexing or research data analysis.
- Repeat the process: Once the web crawler has finished crawling the initial set of URLs, it can start the process again, either by revisiting the same URLs to check for updates, or by crawling a new set of URLs.
The web crawler works by automatically visiting and collecting data from websites, following links, and organizing the information in a database or index. This makes it possible to browse and search the web efficiently and effectively.
Why is web crawling important
Web crawling plays a critical role in the functioning of the internet, as it allows search engines to index and categorize web pages, making it easier for users to find the information they are looking for. By systematically exploring the web and collecting information from a wide range of sources, web crawlers enable businesses, researchers, and individuals to gather large amounts of data quickly and efficiently.
This data can be used for a wide range of purposes, including market research, trend analysis, and sentiment analysis. Web crawling is also important for detecting and preventing fraud, identifying security threats, and monitoring regulatory compliance. In summary, web crawling is a crucial tool for gathering and analyzing data from the web, enabling businesses and individuals to make more informed decisions and take advantage of new opportunities.
Web Scraping vs Web Crawling
While the terms “web scraping” and “web crawling” are sometimes used interchangeably, they refer to different processes.
Web scraping is the process of extracting specific data from web pages, often using automated software or tools. Web scraping usually involves targeting specific websites or pages, and extracting only the relevant data, such as product prices or customer reviews.
Web crawling, on the other hand, is the process of systematically browsing the internet to collect information from websites, without necessarily targeting specific pages or data. Web crawlers follow links from one web page to another, and collect information on a wide range of topics, such as web page content, metadata, and URLs.
While web scraping is often used to extract data for specific purposes, such as market research or data analysis, web crawling is usually used for more general purposes, such as search engine indexing or website optimization.
Web crawling applications
Web crawling has a wide range of applications across various industries and fields, including:
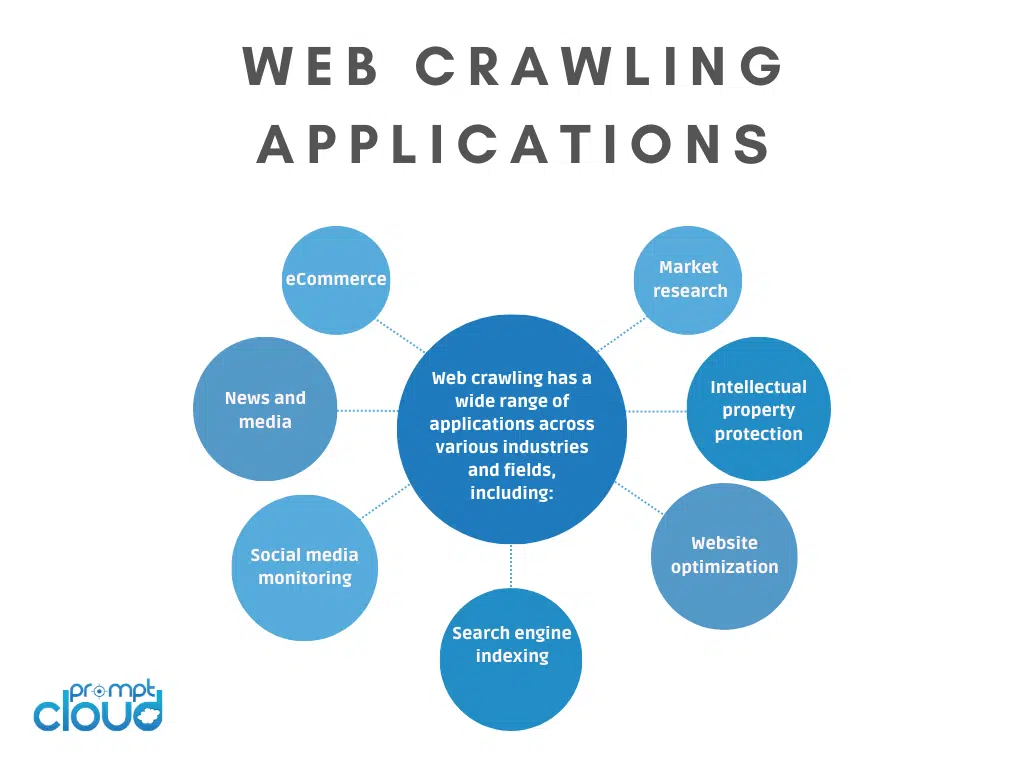
- Search engine indexing: Web crawling is essential for search engines like Google, Bing, and Yahoo to index web pages and make them searchable.
- Website optimization: Web crawling can help website owners optimize their sites for search engines and improve their overall online presence.
- Market research: Web crawling can be used to collect data on competitors, prices, and market trends, helping businesses make informed decisions about their products and services.
- Social media monitoring: Web crawling can be used to gather data on social media platforms, such as user activity, engagement rates, and sentiment analysis.
- News and media: Web crawling is important for news and media organizations that need to stay up-to-date on the latest events and trends.
- E-commerce: Web crawling is crucial for e-commerce businesses that need to gather product information, prices, and other data from competitor websites to stay competitive.
- Intellectual property protection: Web crawling can be used to identify and prevent intellectual property violations, such as copyright infringement and trademark infringement.
Web crawling is a powerful tool that can be used in a wide range of applications and industries. It provides valuable data and insights that are essential for decision-making, research, and analysis, and helps to keep the internet organized, accessible, and secure.
Building an in-house web crawler or using web crawling services: which one to choose?
For organizations that need to crawl the web on a large scale, using web crawling services may be a better option than building an in-house web crawler. Web crawling services have the advantage of being able to handle large volumes of data quickly and efficiently, which can be particularly useful for organizations that need to crawl a large number of websites or web pages. Additionally, web crawling services can offer a wide range of features and customization options, making it easier for organizations to tailor their web crawling operations to their specific needs.
Using web crawling services can also be more cost-effective than building an in-house web crawler. Building an in-house web crawler requires significant investments in hardware, software, and personnel, which can be expensive, particularly for organizations with large-scale needs. On the other hand, web crawling services offer a more affordable solution, as organizations only pay for the services they need, without having to worry about the upfront costs of building and maintaining an in-house solution.
Web crawling services also offer the advantage of being able to handle ongoing maintenance and support, which can be particularly beneficial for organizations with large-scale needs. With web crawling services, organizations don’t have to worry about maintaining their web crawlers or keeping them up-to-date, as the service provider handles these tasks. This can save organizations time and resources that can be allocated towards other areas of their business.













