



Table of Contents
show
In the ever-evolving landscape of e-commerce, data is the cornerstone of competitive advantage. Among the plethora of online marketplaces, Amazon stands as a giant, hosting an expansive array of products, customer reviews, and pricing strategies. For e-commerce businesses looking to thrive, scraping publically available data from Amazon is not just an option; it’s a strategic imperative. In this blog, we delve into how Amazon data scraping can unlock new opportunities for e-commerce businesses.

Source: www.brightdata.com
The Power of Amazon Data
Amazon’s vast repository of product listings, reviews, and consumer behavior data is a goldmine for e-commerce businesses. By strategically analyzing this data, businesses can gain insights into market trends, pricing dynamics, customer preferences, and competitive strategies. However, manually navigating this ocean of data is impractical. This is where custom web scraping tools and services come into play.
How to Scrape Amazon for Product Data
Scraping Amazon for product data can unlock valuable insights for market analysis, competitive intelligence, and price monitoring. However, given Amazon’s dynamic nature and rich JavaScript-based interfaces, extracting this data requires a strategic approach. Here’s a concise guide on how to scrape Amazon for product data effectively.
Understanding Amazon’s Structure
Before initiating a scrape, familiarize yourself with Amazon’s website structure, including how products are categorized and how URLs are formatted. This understanding will help you navigate the site programmatically and target your data extraction more accurately.
Choosing the Right Tools
For Amazon’s JavaScript-rich environment, consider using tools that can render JavaScript like a real browser. Headless browsers such as Puppeteer for Node.js or Selenium WebDriver are excellent choices. They can interact with the webpage, allowing you to scrape dynamic content loaded via JavaScript.
Handling Pagination and Dynamic Content
Amazon product listings are paginated and often loaded dynamically. Your scraping script needs to handle pagination effectively, either by detecting and following ‘Next’ page links or by manipulating the URL parameters used for pagination. Additionally, implementing waits or delays in your script can ensure that dynamic content is fully loaded before extraction.
Extracting Product Data
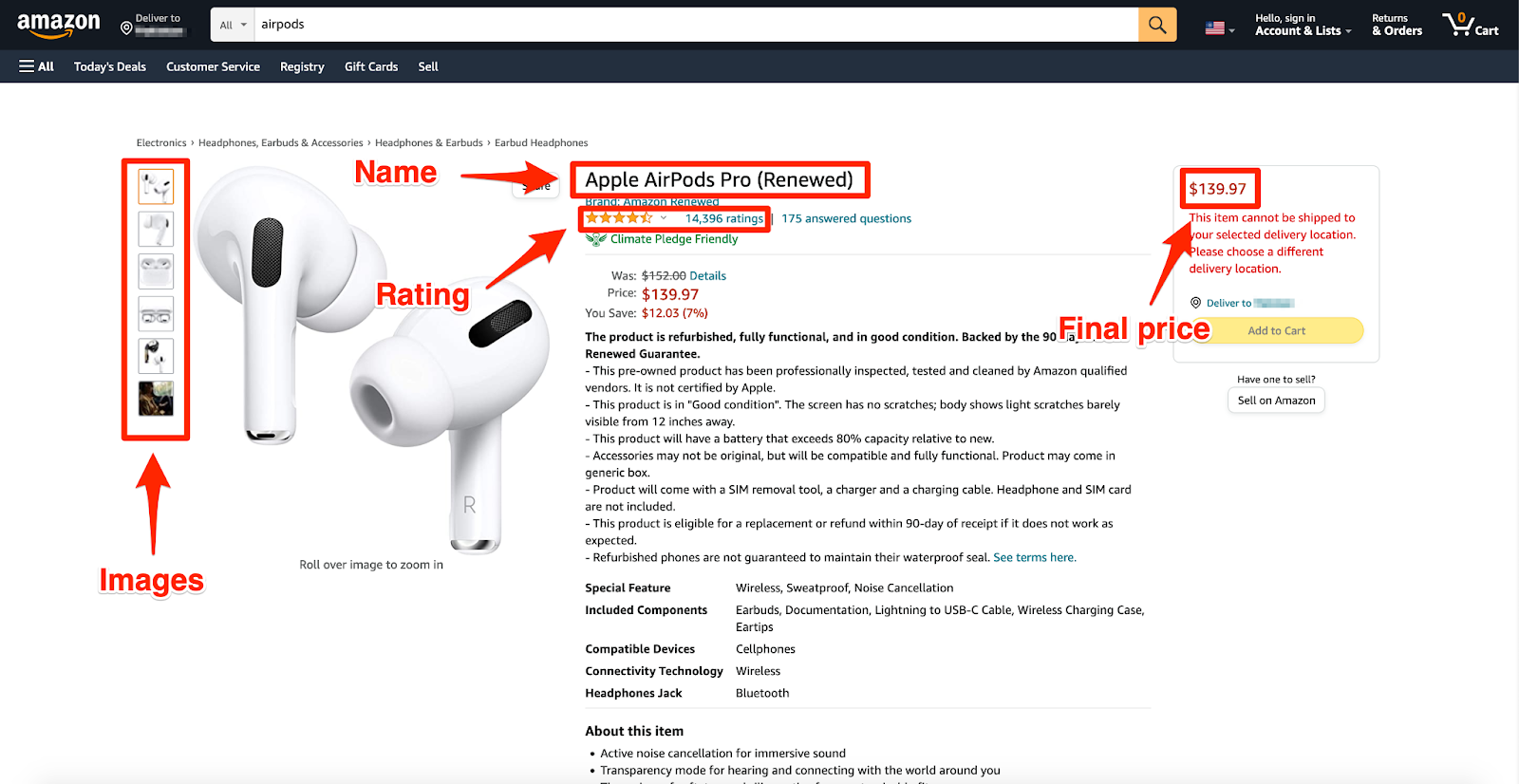
With your tools set up and navigation handled, focus on extracting the specific product data you need. This might include product names, prices, ratings, and reviews. Using the CSS selectors of these data points, you can extract the content using your chosen scraping tool. For instance, with Puppeteer, you would use methods like page.evaluate() to retrieve the text content of elements matching your selectors.
Respecting Amazon’s Policies
It’s crucial to scrape responsibly by adhering to Amazon’s robots.txt file and terms of service. Make sure your scraping activities do not overload Amazon’s servers; implementing polite scraping practices like rate limiting and using a reasonable request delay can help mitigate the risk of being blocked.
Unlocking Opportunities with Amazon Scraping
Source: www.scrapingbee.com
Competitive Analysis
In the bustling e-commerce arena, staying ahead means keeping a close eye on the competition. Imagine being able to peek into your competitor’s playbook – understanding not just what they sell but how they price their products, and what their customers are saying. That’s the power of scraping.
Consider “Brand X,” a startup offering eco-friendly home goods. By scraping Amazon, they noticed a gap in affordable, biodegradable dish soaps. Leveraging this insight, Brand X introduced a competitively priced, high-quality line that quickly became a bestseller, effectively carving out a niche in a crowded market.
Price Optimization
On Amazon, the right price can attract customers and boost sales, while the wrong price can drive them away. Through strategic scraping, businesses can gather pricing data across a spectrum of products, adjusting their own prices in real time to stay competitive and appealing to consumers.
“GadgetPro,” an electronics retailer, uses Amazon data to monitor pricing trends for the latest gadgets. When they notice a leading competitor lowering prices on smartwatches, GadgetPro responds by offering a limited-time discount, successfully retaining customer interest and sales.
Trend Spotting
With millions of transactions daily, Amazon is a goldmine for spotting consumer trends. Data scraping can highlight which products are soaring in popularity, allowing businesses to jump on these trends early.
“Fashion Forward,” an online clothing boutique, identifies a sudden spike in searches for “sustainable fashion” on Amazon. Quickly adapting, they expand their line of eco-friendly apparel, positioning themselves as trendsetters in sustainability.
Enhancing Customer Experience
Amazon reviews are more than just feedback; they’re a direct line to the customer’s wants and needs. By analyzing these reviews, businesses can pinpoint exactly what delights customers or drives them away, and then adjust accordingly.
“Happy Pets,” a pet supply company, notices recurring complaints about the durability of dog toys sold on Amazon. Seeing an opportunity, they develop a new line of nearly indestructible toys, directly addressing this concern and significantly improving customer satisfaction.
Inventory Management
Knowing what’s hot and what’s not can significantly impact inventory decisions. Amazon scraping enables businesses to monitor which products are flying off the shelves and which are languishing, allowing for smarter stock management.
“The Book Nook,” a small online bookstore, uses Amazon data to track trending genres and authors. This insight allows them to stock up on popular titles before peak buying seasons, ensuring they meet demand without overstocking.
Why Choose PromptCloud for Custom Web Scraping Services
At PromptCloud, we understand the complexities and challenges of Amazon data scraping. With robust technology and an expert team, we offer customized Amazon scraping solutions that cater to your specific business needs. Here’s why PromptCloud stands out:
- Compliance and Reliability: Navigating Amazon’s terms of use can be tricky. Our scraping practices are designed to be compliant and ethical, ensuring reliable data without risking account bans.
- Scalability: Whether you’re a startup or an established enterprise, our scalable solutions grow with your business, handling data extraction from a few products to millions.
- Customized Data Extraction: Beyond generic data, we tailor our scraping solutions to capture the specific data points crucial to your business strategy.
- Data Accuracy and Quality: Our sophisticated data cleaning and validation processes ensure you receive accurate and actionable data.
- Seamless Integration: We deliver extracted data in formats that seamlessly integrate with your existing systems, be it for analytics, CRM, or inventory management.
In Summary
Amazon scraping offers a strategic edge in the competitive e-commerce arena. By leveraging the wealth of data available on Amazon, businesses can make informed decisions that drive growth, enhance customer satisfaction, and optimize operations. With PromptCloud, unlock the full potential of Amazon data scraping, transforming data into actionable insights and tangible business outcomes.
Stay ahead in the e-commerce game with PromptCloud. Contact us today to explore how we can empower your business with customized Amazon scraping solutions. Get in touch with us at sales@promptcloud.com
Frequently Asked Questions
Is it legal to scrape from Amazon?
The legality of scraping data from Amazon—or any website, for that matter—depends on various factors, including how you scrape, what data you scrape, and what you intend to do with the data. Here are a few considerations to keep in mind:
Amazon’s Terms of Service:
Amazon’s Terms of Service (ToS) explicitly address data scraping. Generally, Amazon prohibits scraping without explicit permission, as outlined in their ToS. It’s crucial to review these terms carefully to understand what is allowed and what isn’t. Violating these terms could result in legal action from Amazon, including being banned from using their services.
robots.txt File:
Websites use the robots.txt file to indicate which parts of their site can be crawled by bots for indexing by search engines. While not legally binding, respecting the instructions in robots.txt is considered good practice in the web scraping community. Amazon’s robots.txt file provides insights into which parts of their site they prefer not to be scraped.
Copyright Laws:
Data scraped from Amazon, especially product descriptions, images, and reviews, may be subject to copyright laws. Using this data without permission could infringe on the copyright holders’ rights, potentially leading to legal complications.
Data Privacy Regulations:
If your scraped data includes personal information, you must be mindful of data privacy regulations such as GDPR in the European Union or CCPA in California, which impose strict rules on the collection and use of personal data.
Fair Use Doctrine:
In some jurisdictions, the “fair use” doctrine might allow limited scraping for purposes like research, commentary, or criticism, without needing permission. However, what constitutes fair use can vary, and it’s advisable to consult legal counsel if you plan to rely on this doctrine.
What is an Amazon Scraper?
An Amazon scraper is a tool or software designed to extract data from Amazon’s website programmatically. These tools navigate through Amazon’s web pages, systematically collecting information such as product details, prices, reviews, ratings, and seller information. The extracted data is then typically organized and stored in a structured format, such as CSV, Excel, or a database, making it accessible for analysis or further processing.
Purpose and Use Cases
Amazon scrapers serve various purposes, with applications spanning multiple industries and domains. Here are some common use cases:
- Competitive Analysis: Businesses use Amazon Scraper to monitor competitor pricing, product offerings, and customer reviews, allowing them to adjust their strategies in real-time.
- Market Research: By analyzing product trends, popularity, and consumer feedback, companies can identify market gaps and opportunities for new products.
- Price Monitoring: Retailers and e-commerce platforms employ Amazon scraper to track price changes and promotions, enabling dynamic pricing strategies.
- Review Aggregation: Extracting product reviews from Amazon helps businesses gather insights into consumer satisfaction and product quality.
Does Amazon have anti scraping?
Yes, Amazon implements various anti-scraping measures to protect its website and data. As one of the largest e-commerce platforms globally, Amazon holds vast amounts of valuable data, making it a prime target for data scraping efforts. To maintain the integrity of its site and safeguard the data, Amazon has developed several techniques to detect and prevent unauthorized web scraping. These measures include:
- CAPTCHAs: Amazon uses CAPTCHAs (Completely Automated Public Turing test to tell Computers and Humans Apart) to verify that a user is human and not a bot. This can interrupt automated scraping activities by requiring manual input.
- Rate Limiting: Amazon monitors the frequency of requests from a single IP address and may impose rate limits. Excessive request rates can trigger blocks, temporarily or permanently banning the IP address from accessing the site.
- User-Agent Analysis: Amazon checks the user-agent string of incoming requests, which identifies the type of device and browser making the request. Requests with suspicious or bot-associated user-agent strings can be blocked or redirected.
- Dynamic Content and AJAX Calls: Much of Amazon’s content is loaded dynamically using JavaScript and AJAX calls, making it more challenging for simple scraping bots that can only parse static HTML content.
- Legal Agreements and Terms of Service: Amazon’s Terms of Service include clauses that restrict unauthorized scraping of their website content. They reserve the right to take legal action against entities that violate these terms.
- Obfuscation Techniques: Amazon may employ obfuscation techniques that make it harder to identify the patterns and structures within the HTML source code, complicating the extraction process for scrapers.
How does Amazon detect scraping?
Amazon employs several sophisticated anti-scraping techniques to detect and prevent unauthorized data scraping activities on its platform. These measures are designed to protect the website’s data and ensure that the server resources are used efficiently, primarily serving genuine users rather than automated bots. Here are some ways Amazon may detect scraping:
Unusual Access Patterns
Amazon monitors access patterns that deviate from typical human browsing behavior. This can include an unusually high volume of requests from a single IP address, accessing multiple product pages in a short period, or repeatedly querying the same information.
Rate of Requests
Automated scrapers often send requests at a much faster rate than a human would. Amazon can detect this by monitoring the frequency of requests coming from a single user or IP address in a given timeframe. If the request rate exceeds a certain threshold, it’s flagged as potential scraping activity.
Non-Standard User Agents
Web scraping scripts might use a non-standard user agent or one that’s commonly associated with scraping tools. Amazon can detect these user agents and block or challenge them with CAPTCHAs.
Header Analysis
Amazon’s servers can analyze the headers of incoming requests. Missing or unusual headers that are typically present in legitimate browser requests can signal automated scraping activities.
Behavioral Analysis and Interaction
Genuine users interact with web pages in predictable ways, including mouse movements, clicks, and time spent on pages. Automated scripts lack this complexity and can be detected through behavioral analysis algorithms.
CAPTCHA Challenges
Amazon may present CAPTCHA challenges when it detects suspicious activity. CAPTCHAs are designed to be solvable only by humans and can effectively block automated scraping tools.
Analyzing Traffic Sources
Referral data can also be used to detect scraping. Automated tools might not have legitimate referral paths (like from a search engine or another webpage on Amazon), making their requests stand out.
Account and Cookie Analysis
For operations that require an Amazon account, the platform can analyze account activity and cookie integrity. Suspicious account behavior or missing/invalid cookies can trigger anti-scraping measures.















