



Table of Contents
show
Ever since the world wide web started growing in terms of data size and quality, businesses and data enthusiasts have been looking for methods to extract web data smoothly. Today, the best web scraping tools can acquire data from websites of your preference with ease and prompt. Some are meant for hobbyists, and some are suitable for enterprises.
DIY web scraping software belongs to the former category. If you need data from a few websites of your choice for quick research or project, these web scraping tools are more than enough. DIY web scraping tools are much easier to use in comparison to programming your own data extraction setup. You can acquire data without coding with these web scraper tools. Here are some of the best data acquisition software, also called web scraping software, available in the market right now.

Top 7 Web Scraping Tools
1. Outwit Hub
Outwit hub is a Firefox extension that can be easily downloaded from the Firefox add-ons store. Once installed and activated, it gives scraping capabilities to your browser. Extracting data from sites using Outwit hub doesn’t demand programming skills. The set-up is fairly easy to learn. You can refer to our guide on using Outwit hub to get started with extracting data using the web scraping tool. As it is free of cost, it makes for a great option if you need to crawl some data from the web quickly.
2. Web Scraper Chrome Extension
Web scraper is a great alternative to Outwit hub, which is available for Google Chrome, that can be used to acquire data without coding. It lets you set up a sitemap (plan) on how a website should be navigated and what data should be extracted. It can crawl multiple pages simultaneously and even have dynamic data extraction capabilities. The plugin can also handle pages with JavaScript and Ajax, which makes it all the more powerful. The tool lets you export the extracted data to a CSV file. The only downside to this web scraper tool extension is that it doesn’t have many automation features built-in. Learn how to use a web scraper to extract data from the web.
3. Spinn3r
Spinn3r is a great choice for scraping entire data from blogs, news sites, social media and RSS feeds. Spinn3r uses a firehose API that manages 95% of the web crawling and indexing work. It gives you the option to filter the data that it crawls using keywords, which helps in weeding out the irrelevant content. The indexing system of Spinn3r is similar to Google and saves the extracted data in JSON format. Spinn3r’s scraping tool works by continuously scanning the web and updating its data sets. It has an admin console packed with features that lets you perform searches on the raw data. Spinn3r is one of the best web scraping tools Python if your data requirements are limited to media websites.
4. Fminer
Fminer is one of the easiest web scraping tools out there that combines top-in-class features. Its visual dashboard makes web data extraction from sites as simple and intuitive as possible. Whether you want to crawl data from simple web pages or carry out complex data fetching projects that require proxy server lists, Ajax handling and multi-layered crawls, Fminer can do it all. If your project is fairly complex, Fminer is the web scraper software you need.
5. Dexi.io
Dexi.io is a web-based scraping application that doesn’t require any download. It is a browser-based tool for web scraping that lets you set up crawlers and fetch data in real-time. Dexi.io also has features that will let you save the scraped data directly to Box.net and Google Drive or export it as JSON or CSV files. It also supports scraping the data anonymously using proxy servers. The crawled data will be hosted on their servers for up to 2 weeks before it’s archived.
6. ParseHub
Parsehub is a tool that supports complicated data extraction from sites that use AJAX, JavaScript, redirects, and cookies. It is equipped with machine learning technology that can read and analyze documents on the web to output relevant data. Parsehub is available as a desktop client for windows, mac, and Linux and there is also a web app that you can use within the browser. You can have up to 5 crawl projects with the free plan from Parsehub.
7. Octoparse
Octoparse is a visual scraping tool that is easy to configure. The point-and-click user interface lets you teach the scraper how to navigate and extract fields from a website. The software mimics a human user while visiting and scraping data from target websites. Octoparse gives the option to run your extraction on the cloud and on your own local machine. You can export the scraped data in TXT, CSV, HTML, or Excel formats.
Web Scraping Tools vs Data Service Providers
Although web scraping sites tools can handle simple to moderate data extraction requirements, these are not recommended if you are a business trying to acquire data for competitive intelligence or market research. DIY scraping tools can be the right choice if your data requirements are limited and the sites you are looking to crawl are not complicated.
When the requirement is large scale and complicated, tools for web scraping cannot live up to the expectations. If you need an enterprise-grade data solution, outsourcing the requirement to a DaaS (Data-as-a-Service) provider could be the ideal option. Find out if your business needs a DaaS provider.
Dedicated web scraping service providers such as PromptCloud take care of end-to-end data acquisition and will deliver the required data the way you need it. If your data requirement demands a custom-built setup, a DIY tool cannot cover it. Even with the best web scraping tools Python, the customization options are limited and automation is almost non-existent. Tools also come with the downside of maintenance, which can be a daunting task.
A web scraping service provider will set up monitoring for the target websites and make sure that the web scraper setup is well maintained. The flow of data will be smooth and consistent with a hosted solution.
Here are some of the benefits of using DaaS services such as PromptCloud for web scraping over DIY web scraping tools:
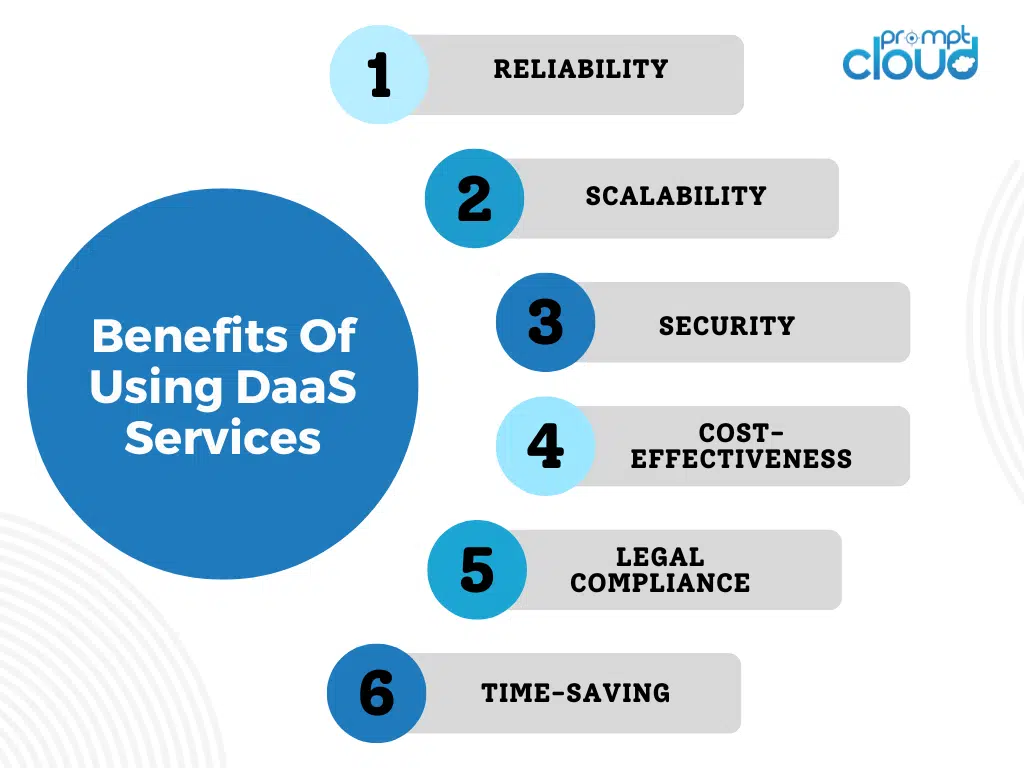
- Reliability: DaaS providers are more reliable than web scraping tools as they provide access to high-quality data that is accurate, timely, and consistent. In contrast, web scraping tools may be affected by changes in website structure or coding, leading to inconsistent or incomplete data.
- Scalability: DaaS services are highly scalable and can handle large volumes of data with ease. This makes it possible to extract data from multiple sources simultaneously, saving time and effort. Web scraping tools, on the other hand, may struggle to handle large volumes of data, resulting in slower processing times and increased risk of errors.
- Security: DaaS services provide better security features than web scraping tools, including encryption, authentication, and authorization. This makes it possible to protect sensitive data and comply with data privacy regulations. Web scraping tools may lack these security features, leaving businesses vulnerable to data breaches and cyber-attacks.
- Cost-effectiveness: DaaS services can be more cost-effective than web scraping tools as they offer a pay-per-use pricing model. This means businesses only pay for the data they need, reducing the risk of wasted resources or overspending. Web scraping tools often require upfront costs and ongoing maintenance expenses, making them less cost-effective over time.
- Legal compliance: DaaS providers are responsible for ensuring that the data they collect is obtained legally and ethically, which can be challenging for web scraping tools. DaaS providers have experience in navigating legal and ethical issues related to web scraping, which can help you avoid legal issues.
- Time-saving: DaaS providers can help you save time by automating the web scraping process. This can be particularly useful if you need to scrape data frequently or in large volumes. With web scraping tools, you may need to manually configure each scrape, which can be time-consuming and error-prone.
Conclusion
While DIY web scraping sites tools can be useful for some businesses, Data as a Service (DaaS) providers offer several key advantages that make them a superior option. DaaS providers can offer scalable, reliable, and high-quality web scraping services that are tailored to your specific needs. They can also provide technical support, legal compliance, and integration with your existing systems, which can save you time and money.
Additionally, DaaS providers can customize their services and offer flexible pricing, making it a cost-effective option for businesses of all sizes. By leveraging the expertise and infrastructure of DaaS providers, businesses can obtain the scraped data they need with greater ease and accuracy, allowing them to make more informed business decisions.
Frequently Asked Questions
1. What does a data scraper do?
A data scraper, often referred to as a web scraper, is a tool or software that automates the process of extracting data from websites. Here’s what a data scraper does:
1. Data Extraction
A data scraper automatically navigates through websites and extracts specific information, such as text, images, links, or structured data (like tables). This data is typically stored in a structured format, such as a spreadsheet or database, making it easier to analyze and use.
2. Automating Data Collection
Instead of manually copying and pasting information from a webpage, a data scraper can automate this process, saving significant time and effort. It can be programmed to extract data from multiple pages, handle large volumes of information, and even follow links to scrape data from multiple levels of a website.
3. Handling Various Data Types
Data scrapers can be configured to handle different types of data, including:
- Text: Extracting text content from articles, blogs, or product descriptions.
- Images: Downloading images or extracting image URLs.
- Tables: Collecting data from tables, such as price lists, product catalogs, or financial reports.
- Links: Extracting hyperlinks for further exploration or scraping.
4. Data Cleaning and Processing
Many advanced data scrapers include features for cleaning and processing the extracted data. This might involve removing duplicates, normalizing text, or filtering out irrelevant information, ensuring that the final dataset is accurate and usable.
5. Providing Data for Analysis
Once the data is scraped, it can be exported into various formats such as CSV, Excel, JSON, or directly into a database. This data can then be used for analysis, reporting, machine learning, or other business intelligence activities.
6. Maintaining Updated Data
Data scrapers can be scheduled to run at regular intervals, ensuring that the extracted data is always up to date. This is particularly useful for tracking changing information like stock prices, product availability, or news updates.
7. Legal and Ethical Considerations
While data scrapers are powerful tools, they must be used responsibly. Scrapers should respect the website’s terms of service, avoid overloading servers with excessive requests, and ensure compliance with legal and ethical standards, especially concerning data privacy.
A data scraper is a tool that automates the extraction of information from websites, transforming unstructured web data into structured formats for analysis or other uses. It saves time, handles large volumes of data, and can keep data updated by running at regular intervals. However, it’s important to use data scrapers ethically and within legal boundaries.
2. Is data scraping illegal?
Data scraping is not inherently illegal, but its legality depends on several factors, including how and what you scrape, the website’s terms of service, and the jurisdiction in which you are operating. Here’s a breakdown of key considerations:
1. Website Terms of Service (ToS)
- Terms of Service Compliance: Many websites have terms of service that explicitly prohibit web scraping. Violating these terms can result in legal action, especially if the website decides to enforce them.
- Permission: Some websites may allow scraping but require explicit permission or adherence to specific guidelines.
2. Public vs. Private Data
- Public Data: Scraping publicly available data from websites is generally legal, especially if the data is not behind a login or paywall and the website does not explicitly prohibit scraping.
- Private Data: Scraping data that is behind login credentials, paywalls, or that requires specific user consent is usually illegal without proper authorization.
3. Impact on Website Operations
- Server Load: Aggressive scraping that overwhelms a website’s server or disrupts its normal operation can lead to legal issues, as this can be considered a denial-of-service (DoS) attack.
- Ethical Scraping: It’s important to scrape websites responsibly, limiting the number of requests per second and respecting the robots.txt file, which indicates how a website wants its pages to be accessed by automated tools.
4. Jurisdictional Differences
- Laws Vary by Country: The legality of web scraping can vary by jurisdiction. For example, the United States has laws like the Computer Fraud and Abuse Act (CFAA), which has been invoked in some web scraping cases.
- Data Protection Laws: In some regions, data protection laws (like GDPR in Europe) can affect how personal data is scraped and used, especially if it involves scraping personally identifiable information (PII).
5. Precedents and Case Law
- Legal Precedents: There have been several legal cases related to web scraping, with outcomes varying depending on the specifics of the case. Some courts have ruled in favor of companies defending against scraping, while others have ruled in favor of those doing the scraping, particularly in cases involving publicly available data.
- Fair Use: In some cases, scraping may be considered fair use, especially for research or academic purposes, but this is highly context-dependent.
6. Ethical Considerations
- Respect for Data Ownership: Even if scraping is technically legal, it’s important to consider the ethical implications, particularly in terms of data ownership, privacy, and the impact on the website’s operation.
Data scraping is not automatically illegal, but its legality depends on the context in which it is done. Key factors include compliance with website terms of service, the type of data being scraped, the method used, and the legal jurisdiction. Always ensure that your scraping activities are both legal and ethical to avoid potential legal issues.
3. What is the best data scraper?
The “best” data scraper can vary depending on your specific needs, such as the complexity of the data you need to extract, the scale of your project, your technical expertise, and your budget. Below are some of the top data scrapers, each suited to different use cases:
1. BeautifulSoup (Python Library)
- Best For: Developers needing a flexible and customizable tool for smaller-scale projects.
- Pros:
- Highly customizable.
- Well-suited for parsing HTML and XML.
- Integrates well with other Python libraries like Pandas and Scrapy.
- Cons:
- Requires programming knowledge.
- Not as scalable for large-scale scraping without additional tools.
2. Scrapy (Python Framework)
- Best For: Developers looking for a powerful, scalable, and fast web scraping framework.
- Pros:
- Designed for large-scale scraping projects.
- Built-in support for handling requests, data extraction, and data storage.
- Can handle complex crawling with ease.
- Cons:
- Requires programming knowledge.
- Steeper learning curve compared to simpler tools.
3. Octoparse
- Best For: Non-programmers looking for a user-friendly, point-and-click interface.
- Pros:
- No coding required.
- Cloud-based service for large-scale scraping.
- Supports scheduling and automatic updates.
- Cons:
- Pricing can be high for advanced features.
- Limited customization compared to code-based tools.
4. ParseHub
- Best For: Users who need to scrape complex sites with dynamic content.
- Pros:
- No coding required.
- Handles dynamic content (JavaScript-heavy websites).
- Visual, easy-to-use interface.
- Cons:
- Free version has limitations on the number of projects and data points.
- Complex setups might require some learning.
5. WebHarvy
- Best For: Users looking for a simple, visual web scraper.
- Pros:
- Point-and-click interface.
- Automatic pattern detection.
- Can scrape images, text, URLs, and more.
- Cons:
- Windows-only software.
- Less flexibility for highly complex scraping tasks.
6. Diffbot
- Best For: Businesses needing a highly automated and AI-driven data extraction solution.
- Pros:
- Uses AI to automatically extract structured data from web pages.
- Can handle large-scale data extraction across multiple sites.
- API-driven, ideal for integrating with other systems.
- Cons:
- Expensive, best suited for enterprise-level projects.
- Limited manual control over the scraping process.
7. Data Miner (Chrome Extension)
- Best For: Quick, small-scale data extraction tasks directly from the browser.
- Pros:
- Easy to use, with no installation required beyond the Chrome extension.
- Ideal for scraping data tables and lists from webpages.
- Free and paid plans available.
- Cons:
- Limited to what can be done within the browser.
- Not suitable for large-scale or highly complex scraping tasks.
8. Content Grabber
- Best For: Enterprises needing a robust, scalable, and customizable web scraping solution.
- Pros:
- Highly customizable with powerful scripting capabilities.
- Can handle large-scale and complex projects.
- Comprehensive support and documentation.
- Cons:
- High cost, more suited for enterprise use.
- Steeper learning curve.
9. PromptCloud
- Best For: Businesses looking for a fully managed web scraping service.
- Pros:
- Managed service—PromptCloud handles the entire scraping process.
- Highly scalable, ideal for large datasets.
- Customizable to meet specific business needs.
- Cons:
- Requires a service contract, making it more suited for long-term, large-scale projects.
- Pricing is typically on a per-project basis.
The best data scraper depends on your needs. For those who are comfortable with coding and want flexibility, Scrapy or BeautifulSoup are excellent choices. For non-programmers who need an easy-to-use, visual tool, Octoparse or ParseHub are ideal. For enterprise-level projects, PromptCloud or Content Grabber offer robust, scalable solutions.
4. Which tool is best for data scraping?
The “best” tool for data scraping depends on your specific requirements, such as the complexity of the data you need, the scale of your project, your technical skills, and whether you prefer a coding-based or no-code solution. Here’s a breakdown of some of the best tools for different needs:
1. BeautifulSoup (Python Library)
- Best For: Developers looking for a flexible, lightweight tool for simple to moderately complex scraping tasks.
- Key Features:
- Excellent for parsing HTML and XML documents.
- Integrates well with other Python libraries like Requests and Pandas.
- Ideal for smaller, ad-hoc scraping tasks.
- Skill Level: Requires basic to intermediate Python knowledge.
2. Scrapy (Python Framework)
- Best For: Developers needing a powerful, scalable framework for large-scale web scraping projects.
- Key Features:
- Handles complex scraping, crawling, and processing tasks.
- Supports asynchronous requests for faster scraping.
- Built-in support for pipelines, item processing, and exporting data.
- Skill Level: Advanced, suitable for those with strong Python skills.
3. Octoparse
- Best For: Non-programmers or those needing a user-friendly tool for visual web scraping.
- Key Features:
- No coding required; drag-and-drop interface.
- Handles both simple and complex data extraction, including dynamic content.
- Cloud-based option for running scraping tasks on remote servers.
- Skill Level: Beginner to intermediate, no programming skills needed.
4. ParseHub
- Best For: Users needing to scrape data from complex websites with dynamic content.
- Key Features:
- Handles JavaScript-heavy websites.
- Visual interface that’s easy to use for non-technical users.
- Free plan available with limitations on data volume.
- Skill Level: Beginner to intermediate.
5. WebHarvy
- Best For: Users who need a simple, visual scraper for straightforward tasks.
- Key Features:
- Point-and-click interface, no coding required.
- Automatically detects patterns on web pages.
- Scrapes text, images, URLs, and more.
- Skill Level: Beginner.
6. Diffbot
- Best For: Enterprises and developers needing an AI-driven data extraction solution.
- Key Features:
- Uses AI to automatically understand and extract data from any webpage.
- API-based, ideal for integrating into larger data pipelines.
- Handles large-scale extraction efficiently.
- Skill Level: Intermediate to advanced, depending on integration needs.
7. Content Grabber
- Best For: Enterprise users who need a robust, scalable, and customizable tool.
- Key Features:
- Highly customizable with powerful scripting capabilities.
- Can handle large-scale and complex scraping projects.
- Offers extensive support and documentation.
- Skill Level: Intermediate to advanced.
8. PromptCloud
- Best For: Businesses looking for a managed web scraping service that takes care of the entire process.
- Key Features:
- Fully managed service, tailored to your specific needs.
- Handles large-scale data extraction projects.
- Provides high-quality, structured data in the format you need.
- Skill Level: No technical skills required; ideal for businesses that want to outsource scraping.
9. Data Miner (Chrome Extension)
- Best For: Quick, small-scale data extraction tasks directly within the browser.
- Key Features:
- Easy-to-use Chrome extension.
- Perfect for scraping tables and lists from websites.
- Free and paid versions available, depending on data volume needs.
- Skill Level: Beginner.
- For Developers: Scrapy and BeautifulSoup are best for those comfortable with coding and needing powerful, customizable tools.
- For Non-Programmers: Octoparse and ParseHub offer user-friendly interfaces that don’t require any coding skills.
- For Enterprises: PromptCloud and Content Grabber provide scalable, robust solutions ideal for large-scale data extraction needs.
Choosing the best tool depends on your specific use case, technical skills, and project requirements.
5. Why is data scraping illegal?
Data scraping is not inherently illegal, but it can become illegal under certain circumstances, depending on how and what you scrape, as well as the legal and ethical guidelines that apply. Here are some reasons why data scraping might be considered illegal:
1. Violation of Website Terms of Service (ToS)
- Terms of Service: Many websites have terms of service that explicitly prohibit web scraping. If you scrape a website in violation of its ToS, you could face legal consequences. Websites may enforce these terms, and scraping against them could lead to legal action, especially if it causes harm to the website.
2. Accessing Private or Restricted Data
- Unauthorized Access: Scraping data that is behind login credentials, paywalls, or other access controls without proper authorization is generally illegal. This type of activity can be considered unauthorized access to a computer system, which is illegal in many jurisdictions.
3. Intellectual Property Infringement
- Copyrighted Content: Some data on websites is protected by copyright or intellectual property laws. Scraping such data without permission could be considered an infringement, particularly if the data is used in a way that violates the rights of the content owner.
4. Data Protection and Privacy Laws
- Personal Data: In regions with strict data protection laws, such as the European Union’s General Data Protection Regulation (GDPR), scraping personal data (e.g., names, emails, phone numbers) without consent can be illegal. This is especially true if the scraped data is used in a way that violates individuals’ privacy rights.
5. Impact on Website Performance
- Denial of Service: Aggressive or poorly implemented scraping can overwhelm a website’s server, causing performance issues or even making the website inaccessible to other users. This can be considered a form of denial-of-service (DoS) attack, which is illegal.
6. Misuse of Data
- Fraudulent or Malicious Intent: If the data obtained through scraping is used for fraudulent activities, such as phishing, spamming, or identity theft, the act of scraping itself can be considered illegal due to its malicious intent.
7. Breach of Contracts
- Contractual Agreements: In some cases, businesses have contracts or agreements with data providers or partners that explicitly prohibit scraping their data. Violating these agreements can lead to legal disputes or penalties.
8. Jurisdictional Differences
- Legal Variations: The legality of web scraping can vary by country or region. Some jurisdictions may have stricter laws against unauthorized access to data, while others may be more lenient. It’s important to be aware of the specific legal context in the region where you are scraping data.
Data scraping becomes illegal when it violates terms of service, accesses restricted or private data without authorization, infringes on intellectual property rights, breaches data protection and privacy laws, causes harm to the website, or is done with malicious intent. To avoid legal issues, it’s crucial to understand the legal and ethical guidelines governing data scraping, respect website terms of service, and ensure compliance with relevant laws.
6. What are the types of data scraping?
Data scraping can be categorized based on the methods used, the types of data targeted, and the tools or techniques employed. Here’s an overview of the different types of data scraping:
1. Web Scraping
- Description: Extracting data from websites, web pages, or web applications.
- Examples:
- Scraping product prices from e-commerce websites.
- Extracting news articles or blog content.
- Gathering data from social media profiles or posts.
- Tools: BeautifulSoup, Scrapy, Octoparse, ParseHub.
2. Screen Scraping
- Description: Capturing data directly from the screen display of an application, rather than from its underlying data source.
- Examples:
- Extracting text from a terminal window or legacy application.
- Capturing data from software that doesn’t provide an export function.
- Tools: Automation tools like AutoIt, Sikuli, or custom scripts.
3. API Scraping
- Description: Extracting data from APIs (Application Programming Interfaces) provided by websites or services.
- Examples:
- Pulling data from Twitter’s API to analyze trends.
- Extracting weather data from a public API.
- Tools: Postman, cURL, Python’s Requests library.
4. Data Scraping from PDFs and Documents
- Description: Extracting data from structured or unstructured documents like PDFs, Word documents, or scanned files.
- Examples:
- Extracting text from a PDF report.
- Converting scanned invoices into structured data.
- Tools: Tabula, Adobe Acrobat, Tika, PyPDF2.
5. Database Scraping
- Description: Extracting data directly from databases by querying them.
- Examples:
- Extracting user data from a MySQL database.
- Pulling records from a CRM system.
- Tools: SQL queries, database management tools like phpMyAdmin, pgAdmin.
6. Image Scraping
- Description: Extracting data or text from images.
- Examples:
- Using Optical Character Recognition (OCR) to read text from images.
- Scraping product images from e-commerce sites.
- Tools: Tesseract (for OCR), OpenCV, BeautifulSoup (for HTML images).
7. Video and Audio Scraping
- Description: Extracting data, text, or metadata from video or audio files.
- Examples:
- Extracting subtitles or transcripts from videos.
- Analyzing audio files for spoken words or phrases.
- Tools: FFmpeg, Speech-to-text APIs like Google Speech Recognition.
8. Social Media Scraping
- Description: Collecting data from social media platforms like Facebook, Twitter, Instagram, etc.
- Examples:
- Gathering tweets for sentiment analysis.
- Scraping public posts and comments from Facebook or Instagram.
- Tools: Tweepy (for Twitter), BeautifulSoup, APIs provided by the platforms.
9. E-commerce Scraping
- Description: Extracting data specifically from e-commerce sites.
- Examples:
- Tracking competitor pricing and product availability.
- Gathering customer reviews and ratings.
- Tools: Scrapy, Octoparse, ParseHub.
10. Content Aggregation
- Description: Gathering and combining content from various sources for a single, unified view.
- Examples:
- Aggregating news articles from different news websites.
- Collecting job listings from multiple job boards.
- Tools: RSS feeds, Scrapy, Web scraping tools.
11. Dynamic Web Scraping
- Description: Scraping data from websites that generate content dynamically using JavaScript.
- Examples:
- Extracting data from websites that load additional content as you scroll (infinite scrolling).
- Scraping data from sites where content is populated through AJAX calls.
- Tools: Selenium, Puppeteer, BeautifulSoup (with integration for dynamic content).
7. What does data scraping do?
Data scraping is the process of automatically extracting large amounts of data from websites, documents, databases, or other sources. It allows you to gather and structure data that would otherwise be difficult, time-consuming, or impossible to collect manually. Here’s what data scraping does:
1. Collects Data from Websites
- Description: Data scraping automates the process of gathering data from websites, whether it’s extracting product information from e-commerce sites, collecting news articles, or pulling social media posts.
- Example: A company might use data scraping to track competitor pricing across multiple e-commerce platforms.
2. Transforms Unstructured Data into Structured Data
- Description: Scraped data is often unstructured, meaning it’s not organized in a predefined manner (like HTML on a web page). Data scraping tools can parse and organize this data into a structured format, such as a spreadsheet or database.
- Example: Scraping a list of job postings from a website and organizing them into a CSV file with columns for job title, company, location, and salary.
3. Automates Data Collection
- Description: Instead of manually copying and pasting information, data scraping tools automate the process, making it faster and more efficient. This is especially useful for collecting large datasets or frequently updated information.
- Example: A financial analyst might use a scraper to automatically pull stock prices from a financial news site every morning.
4. Enables Real-Time Data Access
- Description: Data scraping can be set up to run at regular intervals, ensuring that you always have access to the most up-to-date information. This is crucial for industries where real-time data is essential, such as finance or e-commerce.
- Example: A company might use scraping to continuously monitor social media for mentions of its brand.
5. Supports Data Analysis and Decision-Making
- Description: By collecting and structuring data, scraping enables businesses and researchers to analyze trends, track changes, and make data-driven decisions. The extracted data can be used for market analysis, sentiment analysis, competitive research, and more.
- Example: A marketing team could scrape and analyze customer reviews across multiple platforms to identify common pain points and improve their products.
6. Enables Content Aggregation
- Description: Data scraping allows for the collection of content from multiple sources to be aggregated into a single location. This is commonly used for news aggregation, job boards, price comparison websites, and more.
- Example: A job aggregator site might scrape job postings from several job boards and display them in a unified search interface.
7. Facilitates Competitive Intelligence
- Description: Businesses can use data scraping to gather intelligence on competitors, such as pricing, product offerings, promotions, and customer feedback. This information can be critical for developing competitive strategies.
- Example: A retailer might scrape competitor websites to monitor price changes and adjust their own pricing strategy accordingly.
8. Assists in Data Mining
- Description: Data scraping can be the first step in data mining, where the extracted data is analyzed to find patterns, correlations, and insights. This can be applied in various fields, including marketing, finance, and research.
- Example: A researcher might scrape data from scientific publications to analyze trends in a particular field of study.
8. What is web scraping?
Web scraping is the automated process of extracting data from websites. It involves using a tool or script to gather information from web pages, such as text, images, links, or structured data (like tables), and then converting this information into a structured format that can be used for further analysis or storage, such as in a spreadsheet or database.
Key Aspects of Web Scraping:
- Automated Data Collection:
- Web scraping tools or scripts automatically browse websites and retrieve specific data points without the need for manual copying and pasting. This automation is particularly useful when dealing with large volumes of data or when data needs to be collected regularly.
- Parsing HTML:
- Websites are built using HTML (Hypertext Markup Language), which structures the content of the pages. Web scraping involves parsing this HTML code to locate and extract the desired data, such as product prices, headlines, or contact information.
- Data Structuring:
- After the data is extracted, it’s often unstructured or semi-structured. Web scraping tools can format this data into a structured format, like CSV, Excel, JSON, or a database, making it easier to analyze or integrate with other systems.
- Handling Dynamic Content:
- Modern websites often use JavaScript to load content dynamically (e.g., content that appears after scrolling or clicking a button). Advanced web scraping techniques and tools can handle such dynamic content, ensuring that all relevant data is captured.
- Use Cases for Web Scraping:
- Price Monitoring: Businesses use web scraping to track competitor pricing on e-commerce sites to adjust their own prices competitively.
- Market Research: Companies scrape data on industry trends, customer reviews, and competitor activities for strategic planning.
- Content Aggregation: Websites aggregate content from various sources, like news articles, job postings, or product listings, using web scraping.
- Sentiment Analysis: Scraping social media posts, reviews, and comments to analyze public sentiment about a brand or product.
- Legal and Ethical Considerations:
- Terms of Service (ToS): Many websites have terms of service that explicitly prohibit web scraping. Scraping in violation of these terms can lead to legal action.
- Data Privacy: Scraping personal data without consent, especially in regions with strict data protection laws like GDPR, can be illegal.
- Ethical Scraping: It’s important to scrape websites responsibly, respecting the site’s load capacity and avoiding actions that might disrupt the site’s normal operation.
9. Is it legal to web scrape?
Web scraping is not inherently illegal, but its legality depends on several factors, including how you scrape, what you scrape, and where you scrape. Here’s a breakdown of the key considerations:
1. Website Terms of Service (ToS)
- Terms of Service Compliance: Many websites have terms of service that explicitly prohibit or restrict web scraping. Scraping a website in violation of its ToS can lead to legal consequences. Website owners may choose to enforce these terms, especially if the scraping activity causes harm to their operations.
- Permission: Some websites allow scraping if you obtain explicit permission or follow specific guidelines. Always check the website’s ToS before scraping.
2. Public vs. Private Data
- Public Data: Scraping publicly accessible data that is not behind a login, paywall, or restricted access is generally legal, especially if the website does not explicitly prohibit it. However, even with public data, it’s important to respect the website’s terms and conditions.
- Private or Restricted Data: Scraping data that is behind a login, paywall, or requires specific user consent is typically illegal without proper authorization. This can be considered unauthorized access to a computer system, which is a violation of laws like the Computer Fraud and Abuse Act (CFAA) in the United States.
3. Intellectual Property Rights
- Copyrighted Content: If the data you’re scraping is protected by copyright or other intellectual property laws, scraping it without permission may constitute an infringement. This is particularly relevant when scraping text, images, or other content that is the intellectual property of the website owner.
- Fair Use: In some cases, scraping might be considered fair use, especially for purposes like research, education, or commentary, but this is a complex legal area and depends on the specific circumstances.
4. Data Protection and Privacy Laws
- Personal Data: In jurisdictions with strict data protection laws, such as the European Union’s General Data Protection Regulation (GDPR), scraping personal data (e.g., names, emails, phone numbers) without proper consent can be illegal. Using this data in a way that violates privacy rights can lead to significant penalties.
- Anonymization: If you’re scraping data that could be considered personal, ensuring that the data is anonymized and does not infringe on individual privacy rights can mitigate some legal risks.
5. Impact on Website Operations
- Server Load: Aggressive scraping that overwhelms a website’s server or disrupts its normal operation can be considered a denial-of-service (DoS) attack, which is illegal. Ethical scraping involves respecting the website’s load capacity and using appropriate delays between requests.
- Robots.txt Compliance: While not legally binding, many websites use a
robots.txtfile to indicate how they want web crawlers and scrapers to interact with their site. Respecting these guidelines is considered good practice.
6. Jurisdictional Differences
- Laws Vary by Country: The legality of web scraping can vary depending on the jurisdiction. Some countries have stricter laws regarding unauthorized access to computer systems, intellectual property rights, and data privacy. It’s essential to be aware of the legal environment in the region where you are scraping.
7. Precedents and Case Law
- Legal Precedents: There have been various legal cases related to web scraping, with outcomes that depend on the specific facts of each case. For example, some courts have ruled in favor of websites that enforce anti-scraping policies, while others have allowed scraping of publicly available data under certain conditions.
10. Do hackers use web scraping?
Yes, hackers can use web scraping as one of their tools, but it’s important to understand that web scraping itself is a neutral technology that can be used for both legitimate and malicious purposes. Here’s how hackers might use web scraping, along with some distinctions between ethical and unethical uses:
1. Malicious Uses of Web Scraping by Hackers
- Harvesting Sensitive Information:
- Hackers might use web scraping to collect sensitive or personal information from websites, such as email addresses, usernames, or other personal details. This data can then be used for phishing attacks, identity theft, or other malicious activities.
- Price Scraping for Unfair Competition:
- In some cases, hackers might scrape pricing information from competitors’ websites to gain an unfair competitive advantage. They might also sell this data to other businesses.
- Content Theft:
- Hackers may use web scraping to steal copyrighted content, such as articles, images, or software code, and then repost it on other websites without permission, infringing on intellectual property rights.
- Credential Stuffing:
- Hackers can scrape usernames from websites and use them in combination with stolen passwords from other breaches in automated attacks to gain unauthorized access to user accounts.
- Scraping for Automated Attacks:
- Web scraping can be used as a precursor to automated attacks, such as gathering information about a website’s structure, identifying potential vulnerabilities, or collecting email addresses for spam campaigns.
2. Legitimate Uses of Web Scraping
- Market Research:
- Businesses use web scraping for competitive analysis, gathering information about market trends, or monitoring competitor pricing and product offerings. This is typically done within the bounds of legal and ethical guidelines.
- Data Aggregation:
- Web scraping is used to aggregate data from multiple sources into one location, such as news aggregators, job boards, or real estate listing sites. This provides users with a consolidated view of information.
- Academic Research:
- Researchers may use web scraping to gather data for studies, such as analyzing trends in online discourse, gathering large datasets for machine learning models, or studying social media activity.
- Monitoring and Compliance:
- Companies may use web scraping to monitor their own web presence, ensure compliance with regulations (e.g., scraping their own site to check for accessibility), or keep track of online mentions of their brand.
3. Distinguishing Between Ethical and Unethical Scraping
- Ethical Scraping:
- Performed in compliance with the website’s terms of service.
- Respects the website’s
robots.txtfile and does not overload servers. - Avoids scraping personal data without consent.
- Is transparent and may involve obtaining explicit permission from the website owner.
- Unethical or Illegal Scraping:
- Violates website terms of service.
- Scrapes private or sensitive data without authorization.
- Is used to facilitate malicious activities such as spam, identity theft, or copyright infringement.
- Disrupts the normal operation of a website, causing harm or damage.



































