



Table of Contents
show
What is Cloud Web Scraping & Crawling?
Cloud web scraping and crawling involve the use of cloud infrastructure to collect data from websites and analyze it efficiently. Unlike traditional on-premises setups, cloud-based solutions leverage distributed computing resources, enhancing scalability and performance.
Cloud services offer automated web crawlers that navigate websites, extracting structured data for analysis. These cloud-based systems provide benefits such as real-time data extraction, reduced latency, and ease of scaling to handle large volumes of requests.
Furthermore, they facilitate seamless integration with analytics tools and databases, enabling sophisticated data processing and insights generation without substantial upfront investment.

Image Source: dev.to
Overcoming the Limitations of Traditional Web Crawling
Traditional web crawling methods present several challenges that hinder efficiency and scalability. These methods often require significant computational resources, resulting in high costs for hardware and maintenance. Additionally, they struggle with handling dynamic websites and JavaScript-heavy content, leading to incomplete or inaccurate data extraction.
Furthermore, traditional crawlers are prone to IP blocking, necessitating frequent proxy rotations, which adds complexity. Another issue is the limited scalability; as data demands grow, these crawlers fail to maintain performance. Traditional methods also lack real-time data handling capabilities, making them unsuitable for applications requiring up-to-date information.
Why Cloud-Based Web Crawling is a Game Changer?
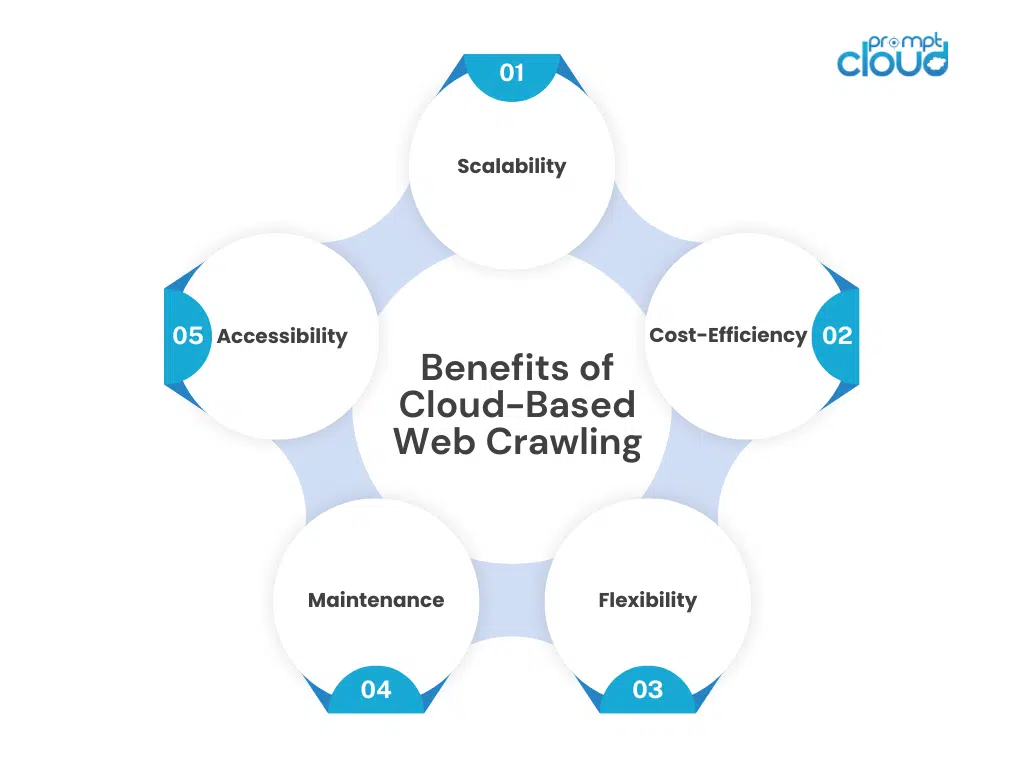
Cloud-based web crawling offers numerous advantages for organizations aiming to boost data collection efficiency and scalability. This approach leverages the power of cloud computing to provide an optimal solution for extensive web scraping tasks.
- Scalability: Enhances the capacity to handle large-scale scraping projects without hardware limitations.
- Cost-Efficiency: Reduces the need for significant upfront investment in physical infrastructure.
- Speed: Accelerates data collection processes due to higher computational power and parallel processing capabilities.
- Flexibility: Offers the ability to adjust resources based on fluctuating needs and demands easily.
- Maintenance: Decreases the burden of server maintenance and upgrades, as cloud providers handle these tasks.
- Accessibility: Ensures data accessibility and collaboration from anywhere, promoting easy data management.
What to Look for in Cloud Web Scraping Tools?
In the search for efficient cloud-based web scraping solutions, certain features are essential to ensure performance, scalability, and reliability. Here are some critical features to consider:
- Scalability: Must handle large volumes of data without performance degradation.
- Ease of Use: User-friendly interfaces and documentation to reduce the learning curve.
- Speed: High-speed data extraction capabilities to save time.
- Data Quality: Accurate and cleansed data outputs.
- Compliance: Adherence to web scraping legal guidelines.
- Customizability: Tailorable scripts and configurations.
- API Integration: Seamless integration with other tools and platforms.
- Support and Maintenance: Reliable customer support and regular updates.
Top Cloud-Based Web Crawling Tools
Cloud-based web crawling tools offer robust solutions for scalable data scraping, eliminating the need for complex local setups.
- AWS:
Amazon Web Services offers scalable infrastructure with services like EC2 for virtual servers and Lambda for serverless execution. Ideal for handling large-scale scraping tasks.
- Google Cloud
Google Cloud Platform provides robust tools like Compute Engine and Cloud Functions, which support high-performance crawling. BigQuery assists in managing and analyzing large datasets.
- Scraper API
Scraper API simplifies web scraping by managing proxies, browsers, and CAPTCHAs. It integrates with popular languages and frameworks, ensuring seamless deployment and execution of scraping tasks efficiently.
Each tool offers unique features catering to different requirements for enhancing scraping efficiency.
How Cloud Solutions Solve Common Web Crawling Challenges?
Web crawling often faces significant hurdles, including IP blocking, bandwidth constraints, data variability, and scalability challenges. Traditional approaches may struggle to manage these issues effectively. Cloud solutions provide scalable infrastructure to manage high traffic and parallelize requests across numerous IP addresses, mitigating the risk of IP bans. They offer:
- Load balancing to handle bandwidth efficiently.
- Versatile storage options to manage diverse data formats.
- Real-time data processing capabilities, enhancing responsiveness.
Furthermore, cloud providers integrate robust security measures, ensuring compliance and data integrity, facilitating seamless and efficient web crawling operations.
Best Practices for Optimizing Web Crawling with Cloud Solutions
To optimize web crawling with cloud solutions, it is key to adopt a strategic approach.
- Distribute Crawling Tasks: Use distributed computing to break down tasks into manageable parts.
- Rate Limiting: Implement rate limiting to avoid overloading target sites.
- Error Handling: Design robust error handling to recover from failures seamlessly.
- Data Caching: Cache-fetched data to minimize repeated requests.
- IP Rotation: Rotate IP addresses to prevent bans.
- Monitoring and Reporting: Continuous monitoring and detailed reporting ensure efficient crawling and troubleshooting.
By following these practices, enhanced efficiency and reliability in web crawling tasks are achieved using cloud infrastructure.

Future Trends in Cloud Web Scraping
In the coming years, cloud web scraping is poised to evolve significantly. Key trends include:
- AI and Machine Learning Integration: Enhancing data extraction precision and context understanding.
- Serverless Architectures: Granting scalable, flexible resource management.
- Increased Privacy and Compliance: Evolving to meet stricter regulations like GDPR and CCPA.
- Enhanced APIs and Microservices: Streamlining spider development and data processing.
- Real-Time Data Scraping: Providing nearly instantaneous data retrieval capabilities.
These trends will shape the cloud web scraping landscape, making it more efficient, user-friendly, and robust while meeting modern demands.
Conclusion
Harnessing the power of scalable cloud web scraping and crawling can substantially elevate your data extraction efforts. PromptCloud excels in this domain by offering robust solutions tailored to meet diverse needs. Partnering with PromptCloud ensures access to advanced technologies, reliability, and customized scraping services that can adapt to the ever-evolving web landscape.Leverage these capabilities to drive innovation, enhance decision-making, and maintain a competitive edge. Discover how PromptCloud can transform your data strategy by exploring their comprehensive service offerings and initiating a conversation with their expert team today. Schedule a demo today!















