




Introduction to Web Crawling
Web crawling is the process that powers many of the digital services we rely on daily, from search engines delivering relevant results to businesses collecting insights for smarter decisions. At its core, web crawling is about navigating through web pages to collect and organize information, enabling businesses and organizations to extract value from the vast ocean of online data.
What is Web Crawling?
Web crawling refers to the automated process of visiting web pages, extracting content, and following links to discover new pages. Often performed by software programs called “crawlers” or “bots,” the primary goal is to gather data systematically and efficiently for indexing, analysis, or other purposes.
For example, search engines like Google use crawlers to find and index content from billions of web pages, making information accessible to users in seconds.
In simple terms, web crawling is the act of programmatically browsing websites to extract data or identify links to further explore. It serves as the backbone for many data-driven technologies by providing raw, organized data.
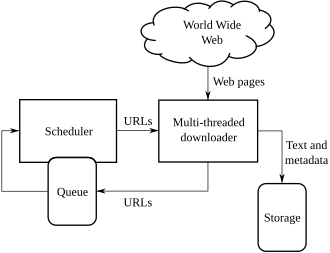
Source: wikipedia
What is Web Crawling and Indexing?
While web crawling involves discovering and collecting data, indexing takes it a step further by organizing that data into a structured format for easy retrieval. Together, crawling and indexing enable systems like search engines, e-commerce platforms, and data aggregators to function seamlessly.
For example:
- Crawling finds a webpage listing products.
- Indexing organizes the details (price, availability, specifications) for users to search efficiently.
Real-World Web Crawling Examples
Web crawling has versatile applications across industries:
- Search Engines: Google’s crawlers scan web pages to ensure their search index is comprehensive and up-to-date.
- Marketplaces: Platforms like Amazon aggregate data from third-party sellers to display accurate inventory and pricing.
- News Aggregators: Websites like Flipboard or Feedly gather articles from multiple sources to present curated content.
- Competitor Monitoring: Businesses collect data on pricing, product features, or reviews to stay competitive.
How Web Crawling Works?
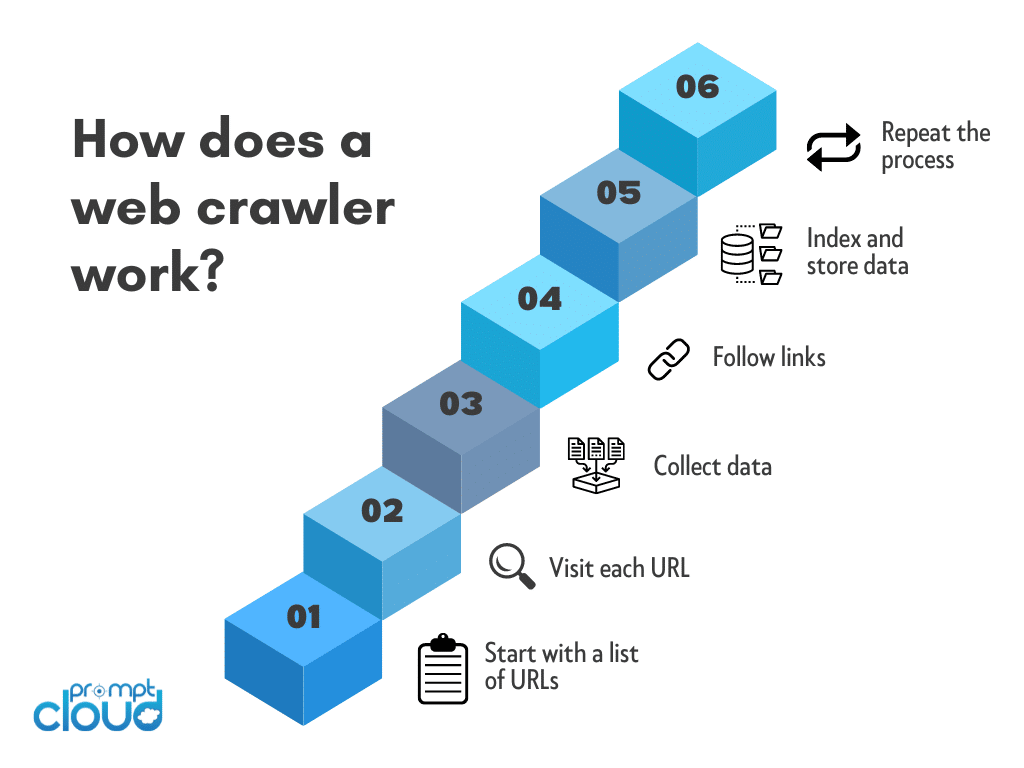
The process of web scraping begins with identifying goals, such as extracting product prices or monitoring competitor updates. Crawlers are programmed to fetch and parse relevant web content, storing it in a usable format for further analysis. This streamlined approach saves time, reduces manual effort, and ensures businesses can focus on decision-making rather than data collection.
Web crawling operates through a systematic, automated process:
- Seed URLs: Crawlers start with a predefined list of URLs.
- Fetching Pages: Crawlers access these pages using HTTP requests and extract their HTML content.
- Parsing Data: Relevant data is identified and extracted based on pre-set rules or filters.
- Following Links: Hyperlinks on the page guide the crawler to discover new pages, expanding the dataset.
- Storage and Processing: The collected data is saved in a structured format for indexing or analysis.
This process repeats iteratively, allowing crawlers to build extensive datasets over time.
Web Crawling vs. Web Scraping: What’s the Difference?
Web crawling and web scraping are closely related terms, but they serve distinct purposes in the realm of data extraction. While both involve gathering information from websites, their methods, goals, and use cases differ significantly. Understanding these differences is crucial for businesses and developers looking to make the most of their data collection strategies.
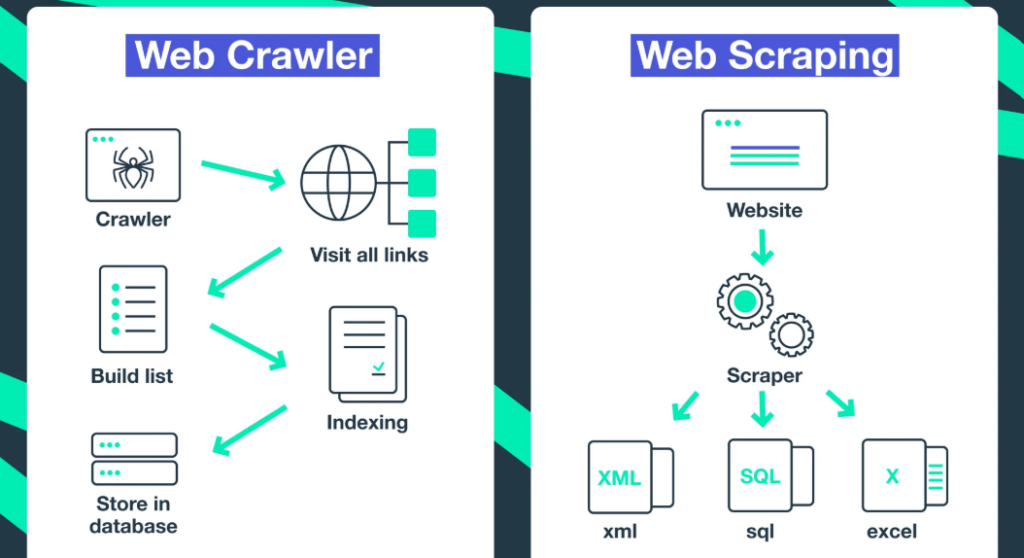
Source: soax
- Web Crawling:
Web crawling is the process of systematically discovering and navigating web pages. A web crawler, also called a “spider,” starts with a list of seed URLs and follows hyperlinks to explore and index content across the web. Crawling is primarily focused on creating a comprehensive map of web pages, which can later be analyzed or scraped for specific information.
Example: Search engines like Google use web crawlers to index web pages, ensuring they are available for search queries.
- Web Scraping:
Web scraping, on the other hand, involves extracting specific data from web pages. Unlike crawling, which gathers and indexes content broadly, scraping is targeted, focusing on collecting structured data like prices, reviews, or product details.
Example: E-commerce platforms scrape competitor websites for price comparison and inventory updates.
Python for Web Crawling and Web Scraping: A Comparison
Python is a popular programming language for both web crawling and web scraping, thanks to its simplicity and robust library ecosystem. Here’s how the two differ when implemented in Python:
- Web Crawling in Python:
- Tools and Libraries: Popular libraries like Scrapy or BeautifulSoup (for smaller tasks) are used for crawling.
- Goal: Automate the process of visiting web pages and following links to discover more pages.
- Output: A list of URLs or raw content (e.g., HTML) that can be indexed or further analyzed.
- Example: Writing a Python script to crawl a blog and collect all the URLs of its articles.
- Web Scraping in Python:
- Tools and Libraries: Libraries like BeautifulSoup, Selenium(for dynamic content), or pandas (for data processing).
- Goal: Extract targeted information from specific pages, such as product names, prices, or customer reviews.
- Output: Clean, structured datasets (e.g., CSV or JSON) ready for analysis or integration into applications.
- Example: Writing a Python script to scrape product details from an e-commerce website and save them in a CSV file.
Top Web Crawling Tools & Technologies
Web crawling is a sophisticated process that requires the right tools and technologies to ensure efficiency, scalability, and accuracy. From open-source frameworks to custom-built solutions, choosing the right web crawling tool depends on your specific needs, such as data volume, complexity, and target use cases.
Here are some of the most popular tools used for web crawling, catering to a range of expertise levels:
- Scrapy (Python):
- A powerful, open-source web crawling and scraping framework.
- Best for developers who need a fast and flexible solution for handling large-scale projects.
- BeautifulSoup (Python):
- Ideal for small-scale projects or beginners.
- Simplifies parsing HTML and XML documents but requires additional setup for crawling.
- Selenium:
- Designed for scraping dynamic content, it simulates user interactions with JavaScript-heavy websites.
- Works across Python, Java, and other programming languages.
- Apify:
- A cloud-based platform offering pre-built actors for common crawling tasks.
- Excellent for those who want to avoid coding and prefer an intuitive interface.
- Octoparse:
- A no-code web crawling tool with a user-friendly interface.
- Great for non-developers looking for quick results.
Best Free Tools for Web Crawling Beginners
For startups or individuals working with limited budgets, free tools can provide a good starting point:
- Heritrix: An open-source, Java-based web crawler developed by the Internet Archive.
- OpenSearchServer: Offers basic crawling functionality with built-in indexing features.
- HTTrack: Primarily used for downloading entire websites but useful for offline analysis.
While free tools are accessible, they often lack advanced scraping features like scalability and dynamic content handling, making premium or custom solutions necessary for complex tasks.
Custom Web Crawling Service for Custom Data Needs
When off-the-shelf tools don’t meet your requirements, custom web crawling software offers a tailored solution. Custom crawlers provide:
- Specific Targeting: Built to extract exactly the data you need.
- Scalability: Handle large datasets and frequent updates effortlessly.
- Integration: Seamlessly integrate into your existing workflows, delivering data in formats like JSON or CSV.
PromptCloud specializes in custom web crawling solutions, ensuring compliance, accuracy, and efficiency tailored to your unique needs.
Top Web Crawling Frameworks for Efficient Data Collection
Web Crawling with Python
Python remains a top choice for web crawling due to its simplicity, rich ecosystem, and versatility.
- Scrapy: Best for scalable crawling and extracting structured data.
- BeautifulSoup: Ideal for parsing and navigating HTML documents.
- Selenium: Handles dynamic content, offering flexibility for websites with JavaScript-based interactions.
Python’s extensive libraries and community support make it ideal for projects ranging from simple to complex.
Web Crawling with Node.js and Java
- Node.js:
- Frameworks: Puppeteer and Cheerio are popular for handling crawling and scraping tasks.
- Best Use Case: JavaScript-heavy websites requiring real-time interactions.
- Java:
- Frameworks: Jsoup for HTML parsing and Apache Nutch for large-scale web crawling.
- Best Use Case: Enterprise-grade crawling requiring robust and scalable solutions.
The right web crawling tool or technology depends on the complexity and scale of your project. While Python frameworks like Scrapy dominate for flexibility and scalability, Node.js and Java offer robust solutions for dynamic and enterprise-level needs. For businesses seeking tailored, scalable solutions, PromptCloud provides custom web crawling software designed to meet diverse requirements while ensuring compliance and reliability.
Do check out our Custom Web Crawling Solutions with PromptCloud.
Proven Web Crawling Techniques and Methodologies
Web crawling is not just about extracting data from websites; it’s about doing so efficiently, ethically, and at scale. Various techniques and methodologies are employed to ensure the process is optimized for different requirements, from dynamic content handling to large-scale distributed crawling.
How to Do Web Crawling?
- Define Your Objective
Determine the purpose of your crawl—whether it’s for indexing, market research, or data collection for AI training. - Identify Target Websites
Create a list of seed URLs or focus on specific domains. Ensure you’re aware of the website’s robots.txt file and follow its rules. - Choose Your Tool or Framework
- For Beginners: Tools like Octoparse or BeautifulSoup (Python).
- For Advanced Users: Frameworks like Scrapy or Puppeteer.
- Write and Execute Your Crawler
Use your chosen tool or programming language to fetch web pages, extract desired content, and store the data in a structured format (e.g., JSON, CSV). - Handle Challenges
Implement techniques for avoiding bot detection, such as IP rotation or user-agent switching. - Process and Store Data
Clean and structure the data for analysis or integration into your system.
Web Crawling Algorithms & Architecture
Efficient web crawling relies on robust algorithms and architecture to manage resources and ensure effective navigation.
- Breadth-First Search (BFS):
- Explores links level by level.
- Ideal for creating a broad overview of a website.
- Depth-First Search (DFS):
- Follows links deeply before returning to higher levels.
- Useful for crawling specific sections of a website.
- Politeness Policy:
- Implements delays between requests to avoid overloading servers.
- Essential for maintaining ethical and efficient crawling.
- Prioritization Algorithms:
- Assign importance to URLs based on factors like page rank, relevance, or freshness.
Advanced Techniques in Web Crawling
- Distributed Web Crawling:
- What It Is: Divides crawling tasks across multiple machines to handle large-scale projects.
- Use Case: Search engines like Google use distributed crawling to index billions of pages efficiently.
- Dynamic Web Crawling:
- What It Is: Extracts data from websites with JavaScript-rendered content.
- Tools: Puppeteer or Selenium for handling dynamic pages.
- Challenges: Requires rendering the page fully to access all content, increasing resource usage.
- Deep Web Crawling:
- What It Is: Crawling content not directly accessible through standard hyperlinks (e.g., behind forms or authentication).
- Techniques: Using automated form submission or API integration to access deeper layers of the web.
Automation in Web Crawling: Benefits & Challenges
- Benefits:
- Scalability: Automate the process to handle larger datasets without manual intervention.
- Efficiency: Save time by scheduling regular crawls and updates.
- Consistency: Ensure accurate and uniform data collection.
- Challenges:
- Bot Detection: Websites may implement CAPTCHAs or IP blocking.
- Maintenance: Websites frequently change their structure, requiring updates to crawlers.
- Compliance: Adhering to data privacy laws and terms of service is essential.
Real World Applications & Use Cases of Web Crawling
Web crawling has become an essential technology powering various industries and use cases. From gathering insights to fueling AI systems, its versatility allows businesses to automate data collection, enabling smarter decision-making and innovation.
Role of Web Crawling in Different Industries
Web crawling is a backbone technology in industries that rely on large-scale data aggregation and analysis. Its applications range from market research and financial analysis to competitive intelligence and trend forecasting.
- Search Engines: Search engines like Google use crawling to index billions of pages, ensuring relevant and updated results for users.
- Travel Industry: Aggregators like Expedia crawl travel sites for real-time pricing and availability data.
- Healthcare: Research institutions use crawling to gather data from publications, patient forums, or clinical trial records.
Applications in Information Retrieval
Information retrieval systems rely heavily on web crawling to organize and access vast amounts of content.
- Content Aggregators: News platforms crawl multiple sources to provide curated content to readers.
- Knowledge Repositories: Platforms like Wikipedia or academic databases leverage crawling for data expansion and validation.
Web Crawling in E-Commerce
E-commerce platforms use web crawling to stay competitive and deliver value to customers.
- Price Monitoring: Retailers track competitor pricing to adjust their own dynamically.
- Product Availability: Ensure accurate inventory updates by monitoring supplier or competitor sites.
- Customer Sentiment Analysis: Crawl reviews and ratings to identify trends and improve product offerings.
Enterprise Web Crawling Use Cases
Large-scale businesses benefit from web crawling in various domains:
- Financial Services: Gather market data, stock prices, and financial news to inform trading strategies.
- Recruitment: Crawl job boards and professional networks for talent acquisition and trend analysis.
- Real Estate: Collect property listings, pricing, and market trends to improve decision-making.
Specialized Web Crawling
Web crawling can be tailored to niche use cases, providing industry-specific solutions:
- Healthcare Crawling: Extract data from research publications, patient forums, or clinical trials.
- Legal Research: Gather data from court rulings, regulations, or statutes.
- Retail Analytics: Monitor store-level availability or regional pricing trends.
Google Web Crawling
Google’s web crawlers (e.g., Googlebot) are among the most advanced, systematically indexing the web to provide fast and relevant search results. Key aspects include:
- Crawl Budget: Prioritizes pages based on quality and relevance.
- Dynamic Crawling: Handles JavaScript and other modern web technologies.
AI and Machine Learning in Web Crawling
AI enhances web crawling by making it smarter, faster, and more adaptive:
- Dynamic Adaptation: AI helps crawlers adjust to website changes without manual reprogramming.
- Sentiment Analysis: Crawled data can be fed into AI models to analyze customer opinions or market sentiment.
- Predictive Crawling: Machine learning prioritizes high-value pages based on historical patterns.
Web Crawling for YouTube and Social Media
Social media and video platforms offer rich data for analysis, and web crawling can unlock this information:
- Sentiment Analysis: Extract user comments to understand public opinion.
- Content Trends: Monitor trending hashtags, keywords, or videos.
- Influencer Marketing: Identify influencers based on engagement metrics or follower data.
From powering search engines to transforming e-commerce strategies, web crawling is a critical enabler across industries. Its applications, combined with advanced technologies like AI and machine learning, make it an indispensable tool for modern businesses.
If you’re looking for scalable and tailored web crawling solutions, PromptCloud offers expertise in specialized crawling for a wide range of use cases, helping businesses extract value from web data effortlessly.
Learn More About PromptCloud’s Custom Web Crawling Solutions
Web Crawling and Compliance: Legal & Ethical Considerations
Web crawling is a powerful technology with vast applications, but it also comes with legal and ethical responsibilities. Navigating the boundaries of what’s permissible is essential to ensure compliance and maintain trust.
Is Web Crawling Legal?
Web crawling itself is not inherently illegal. It is generally considered legal if it complies with the following:
- Terms of Service (ToS): Respect the rules outlined by the website being crawled.
- Public Data: Crawling publicly available data without bypassing restrictions is typically permissible.
- No Harm Principle: Ensure that your crawling activities do not disrupt the website’s functionality or overload its servers.
However, laws vary across jurisdictions, and what’s legal in one country may be restricted in another.
Understanding Web Crawling Legal Issues
Legal concerns surrounding web crawling often involve:
- Copyright Infringement: Copying content from a website without permission may violate intellectual property laws.
- Data Privacy: Collecting personal information without consent may breach privacy regulations like GDPR (EU) or CCPA (California).
- Terms of Service Violations: Crawling websites that explicitly prohibit bots in their ToS can lead to legal disputes.
Key Example: The hiQ Labs vs. LinkedIn case highlighted the importance of balancing public data collection with privacy and platform rights.
Is Web Crawling Illegal in Certain Countries?
While web crawling is generally legal, specific regulations apply in different regions:
- European Union: GDPR mandates that any personal data collection must be done with consent.
- United States: The Computer Fraud and Abuse Act (CFAA) prohibits unauthorized access to systems, which may include bypassing anti-scraping measures.
- China: Stringent cybersecurity laws can limit crawling activities, especially for foreign entities.
It’s crucial to understand local laws and consult legal counsel when crawling in different regions.
How Websites Prevent Web Crawling and Protect Their Data?
Websites can implement various methods to prevent unauthorized crawling, such as:
- Robots.txt: A file that specifies which parts of the website are off-limits to crawlers.
- CAPTCHAs: Automated challenges to differentiate humans from bots.
- IP Blocking: Denying access to bots identified by their IP addresses.
- Dynamic Content Rendering: Using JavaScript to make crawling more difficult.
These measures are designed to protect proprietary content and ensure servers aren’t overloaded.
Ethical Guidelines for Web Crawling

Ethical web crawling goes beyond legality—it focuses on responsible practices that respect the rights of website owners and users. Key guidelines include:
- Follow Robots.txt: Even if it’s not legally binding, respecting robots.txt directives is a good ethical practice.
- Rate Limiting: Crawl at a pace that avoids overwhelming the website’s server.
- Avoid Personal Data: Exclude personally identifiable information (PII) from your crawling activities unless explicitly authorized.
- Transparency: Inform website owners or seek permission for large-scale crawling activities.
Web crawling is a legal and ethical tool when done responsibly. By understanding the rules and following best practices, businesses can harness the power of web crawling without overstepping boundaries. At PromptCloud, we prioritize compliance and ethics in all our web crawling solutions, ensuring your data needs are met responsibly and effectively.
Learn More About Our Ethical Web Crawling Solutions
Best Web Crawling Services to Accelerate Data Collection
Web crawling services simplify the process of collecting, organizing, and delivering data from the web, making it accessible and actionable for businesses. From automated solutions to fully customized services, these offerings cater to a variety of industries and use cases.
The web crawling landscape includes a mix of providers offering different levels of service. Some of the top providers include:
- PromptCloud: Custom, scalable web crawling solutions designed for diverse business needs, with a focus on compliance and accuracy.
- Bright Data (formerly Luminati): Proxy services combined with data extraction capabilities for large-scale projects.
- ScrapingBee: A straightforward service that simplifies web scraping and crawling with browser automation.
- Apify: Offers pre-built and customizable actors for crawling and scraping specific data sources.
Automated Web Crawling Solutions
Automated web crawling eliminates the need for manual intervention by continuously collecting data at predefined intervals. Key benefits include:
- Efficiency: Automates repetitive tasks, freeing up time for analysis.
- Consistency: Delivers structured data reliably, without interruptions.
- Integration: Provides seamless delivery through APIs or other formats.
Automated solutions are ideal for industries requiring regular updates, such as price monitoring or news aggregation.
Custom Web Crawling Solutions
Custom web crawling services offer tailored workflows to meet specific data needs. They are particularly useful for:
- Complex Projects: Handling dynamic or JavaScript-heavy websites.
- Industry-Specific Data: Extracting specialized information, such as healthcare records or real estate listings.
- Unique Formats: Delivering data in formats that integrate directly into existing systems.
At Promptcloud, We work closely with businesses to design custom solutions that align with their goals, ensuring scalability and compliance.
Custom Web Crawling Service for Businesses
Businesses often require bespoke crawling solutions for:
- Competitor Analysis: Extract data on pricing, features, and customer sentiment.
- Market Research: Aggregate insights from various sources to identify trends.
- Content Aggregation: Collect and organize data for publishing or analysis.
Custom services ensure that the data is relevant, structured, and actionable, helping businesses make better decisions.
How to Choose the Best Web Crawling Services for Your Needs?
Choosing the best web crawling service depends on your requirements. Look for providers that offer:
When selecting a web crawling provider, consider the following factors:
- Experience and Expertise:
- Choose a provider with a proven track record in delivering reliable solutions.
- Look for industry-specific expertise.
- Customization Capabilities:
- Ensure the provider offers tailored workflows rather than one-size-fits-all solutions.
- Compliance and Ethics:
- Verify their adherence to data privacy regulations like GDPR and CCPA.
- Scalability:
- Ensure the service can handle your growing data needs over time.
- Support and Maintenance:
- Opt for providers with 24/7 support to address issues quickly.
- Delivery Methods:
- Check for flexibility in data delivery, such as APIs, FTP, or other preferred formats.
Conclusion
Web crawling services empower businesses by automating and optimizing data collection. Whether you need real-time updates, specialized datasets, or fully customized solutions, choosing the right service provider is key to success.
At PromptCloud, we offer tailored, scalable, and compliant web crawling solutions that align with your business goals, helping you unlock actionable insights effortlessly. Contact us today or Get in touch with us at sales@promptcloud.com















