


Table of Contents
show
In today’s fast-paced digital landscape, having access to real-time data is crucial for making informed business decisions. Craigslist, one of the most popular classified advertisement websites, offers a treasure trove of data for businesses looking to gain insights into various markets. In this article, we will explore more about Craigslist scraper.
What is Web Scraping?
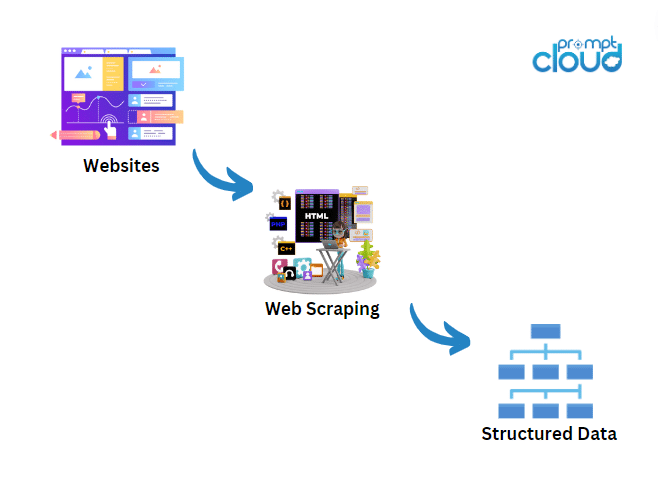
Web scraping is a technique used to extract large amounts of data from websites, transforming it into a structured format for analysis and utilization. This method involves sending HTTP requests to a website’s server, retrieving the HTML content, and then parsing it to extract the necessary information. With web scraping, businesses can automate data collection processes, gaining access to valuable insights without the need for manual data entry.
Why Craigslist?
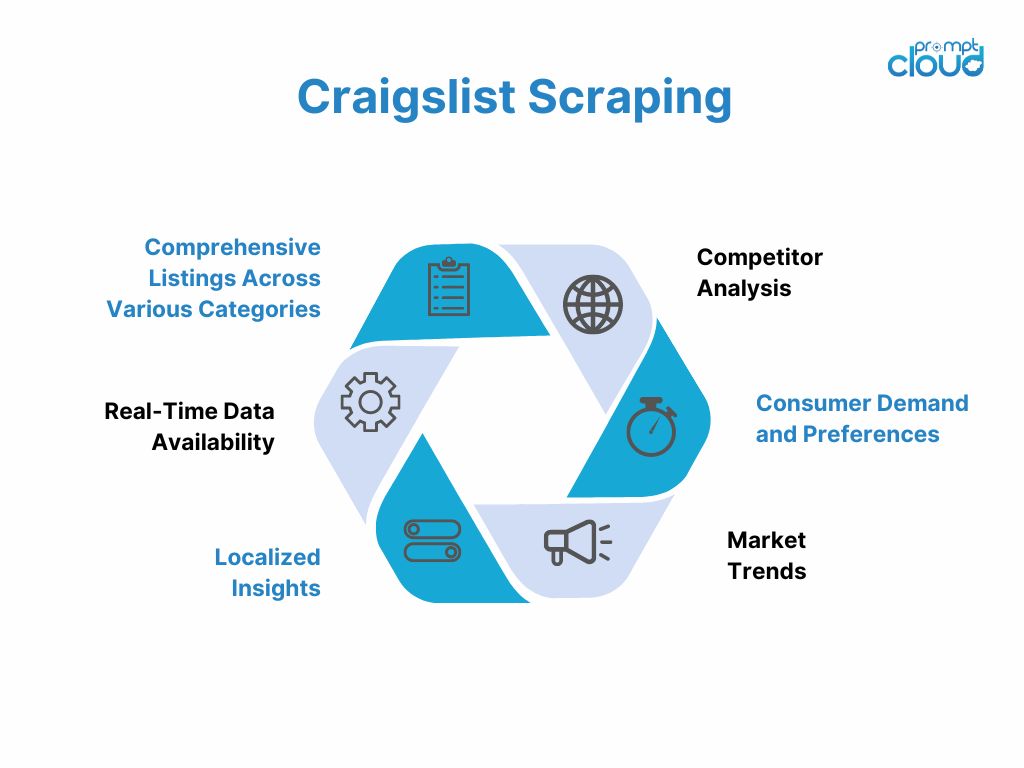
Craigslist is one of the most prominent classified advertisement websites globally, offering an extensive range of categories and listings. Here’s why Craigslist scraper is ideal for web scraping and let’s learn how businesses can benefit from the wealth of data it provides:
Comprehensive Listings Across Various Categories
Craigslist hosts millions of listings in categories such as housing, jobs, services, items for sale, community events, and more. This wide array of categories means businesses can gather diverse data points, making it possible to conduct detailed market analysis and gain insights into different sectors. Craigslist scraper can help businesses with various datasets.
- Real-Time Data Availability
The dynamic nature of Craigslist ensures that new listings are added continuously, providing up-to-date information. Businesses can leverage this real-time data to monitor market changes, track inventory levels, and respond swiftly to emerging trends or opportunities. For instance, real estate agents can use this data to analyze housing market fluctuations and adjust their strategies accordingly.
- Localized Insights
Craigslist operates in hundreds of cities across various countries, allowing businesses to collect data at a local level. This localization is particularly useful for companies looking to understand regional market dynamics, consumer preferences, and competition. Local businesses can use this data to tailor their marketing campaigns and product offerings to meet the specific needs of their target audience. Craigslist scraper can extract information from the website based on business needs.
- Competitor Analysis
With Craigslist scraper, businesses can keep a close eye on their competitors. They can monitor competitor pricing, product availability, and promotional strategies. This competitive intelligence enables businesses to adjust their own pricing strategies, launch timely promotions, and stay ahead of the competition.
- Consumer Demand & Preferences
Craigslist is a valuable resource for understanding consumer demand and preferences. By analyzing the types of listings that receive the most attention and engagement, businesses can identify popular products and services. This information can guide product development, inventory management, and marketing strategies to better meet customer needs.
- Market Trends
Tracking the volume and types of listings over time on Craigslist can reveal market trends. For example, an increase in job postings in a particular industry may indicate economic growth in that sector. Businesses can use these insights to forecast market developments, make strategic decisions, and capitalize on emerging opportunities.
- Historical Data Analysis
Craigslist archives past listings, making it possible to perform historical data analysis. Businesses can study trends over time, compare past and present data, and gain insights into market evolution. This historical perspective can be invaluable for strategic planning and long-term decision-making.
Use Cases for Scraping Craigslist
- Real Estate Market Analysis
Real estate professionals can use Craigslist scrapers to monitor housing prices, rental rates, and availability in different regions. This information helps in assessing market conditions, identifying investment opportunities, and providing clients with accurate market insights.
- Job Market Insights
Recruitment agencies and HR departments can scrape job listings to understand demand for various roles, salary trends, and skill requirements. This data supports recruitment strategies, workforce planning, and competitive salary benchmarking.
- Product Pricing Strategies
E-commerce businesses can track competitor prices for similar products listed on Craigslist. By understanding competitor pricing strategies, businesses can adjust their own prices to stay competitive and attract more customers.
- Service Demand Analysis
Service providers, such as contractors and freelancers, can analyze Craigslist listings to gauge demand for their services. This information helps in targeting marketing efforts, setting competitive rates, and identifying potential clients.
Web Scraping Craiglist – Step by Step Process
- Setting Up the Environment
First, ensure you have Python installed on your machine. Then, install the necessary libraries using a pip
- Sending HTTP Requests
We will start by sending a request to a Craigslist page to retrieve its HTML content. Let’s scrape the listings from the housing section in New York City.
import requests
from bs4 import BeautifulSoup
url = “https://newyork.craigslist.org/d/housing/search/hhh”
response = requests.get(url)
soup = BeautifulSoup(response.text, ‘html.parser’)
- Parsing HTML Content
Next, we will parse the HTML content to extract the data we need, such as the title, price, and location of each listing.
listings = soup.find_all(‘li’, class_=’result-row’)
for listing in listings:
title = listing.find(‘a’, class_=’result-title’).text
price = listing.find(‘span’, class_=’result-price’).text
location = listing.find(‘span’, class_=’result-hood’).text if listing.find(‘span’, class_=’result-hood’) else ‘N/A’
print(f”Title: {title}, Price: {price}, Location: {location}”)
- Handling Pagination
Craigslist listings are spread across multiple pages. To scrape data from all pages, we need to handle pagination.
import time
def scrape_page(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, ‘html.parser’)
return soup
base_url = “https://newyork.craigslist.org/d/housing/search/hhh”
page_number = 0
while True:
url = f”{base_url}?s={page_number * 120}”
soup = scrape_page(url)
listings = soup.find_all(‘li’, class_=’result-row’)
if not listings:
break
for listing in listings:
title = listing.find(‘a’, class_=’result-title’).text
price = listing.find(‘span’, class_=’result-price’).text
location = listing.find(‘span’, class_=’result-hood’).text if listing.find(‘span’, class_=’result-hood’) else ‘N/A’
print(f”Title: {title}, Price: {price}, Location: {location}”)
page_number += 1
time.sleep(2) # To avoid overwhelming the server
- Storing Data in a DataFrame
To analyze the data effectively, we can store it in a Pandas DataFrame.
import pandas as pd
data = []
while True:
url = f”{base_url}?s={page_number * 120}”
soup = scrape_page(url)
listings = soup.find_all(‘li’, class_=’result-row’)
if not listings:
break
for listing in listings:
title = listing.find(‘a’, class_=’result-title’).text
price = listing.find(‘span’, class_=’result-price’).text
location = listing.find(‘span’, class_=’result-hood’).text if listing.find(‘span’, ‘result-hood’) else ‘N/A’
data.append([title, price, location])
page_number += 1
time.sleep(2)
df = pd.DataFrame(data, columns=[‘Title’, ‘Price’, ‘Location’])
print(df.head())
- Using Selenium for Dynamic Content
Some Craigslist pages might have dynamic content that requires JavaScript execution. For these cases, we can use Selenium.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
driver.get(“https://newyork.craigslist.org/d/housing/search/hhh”)
soup = BeautifulSoup(driver.page_source, ‘html.parser’)
driver.quit()
listings = soup.find_all(‘li’, class_=’result-row’)
# (Process listings as before)
Conclusion
Craigslist scraper provides valuable insights into various markets. By following this approach, you can efficiently extract and analyze data while adhering to ethical guidelines. Whether you’re tracking housing prices, job listings, or marketplace trends, web scraping can be a powerful tool in your data analysis arsenal.
At PromptCloud, we specialize in providing web scraping solutions tailored to your business needs. Contact us today to learn how we can help you unlock the full potential of web data.


































