


Table of Contents
show
Data collection and curing is the core foundation of most businesses. Database building thus is an important function and activity where enterprises invest heavily. With information now available on the Internet and easily obtained, it raises the importance of having professionals who crawl data and offer web scraping services.
Once the data is accessed, though, it is important to filter out the relevant data based on the business need. Although Many DaaS provider convert the unstructured web data into meaningful structured data it is recommended to be internally equipped to use the data to its maximum.
This understanding has given rise to the field of Data Mining. Data Mining is designed to explore large amounts of data in search of consistent patterns and connections between the variables and validate the findings by applying the detected patterns to the new sets of the data. Once these connections are established and understood, the end goal is to be able to predict the possible outcomes using predictive analysis techniques.
Together, both Data Mining and predictive analysis aid in making marketing campaigns more efficient. While predictive analysis helps simulate and understand what may happen, data mining helps identify exciting data patterns and connections.
The process of Data Mining and Predictive analysis consists of 3 steps
Exploration
Once a database is compiled, it needs to be cleaned, analysed and potential connections need to be built. This process involves filtering the relevant data and identifying the possible predictors. Data Exploration also sets a premise for preliminary feature selection to manage number of variables. This data is then prepared for statistical analysis using a wide variety of graphical and statistical parameters. This helps identify the most relevant variables and setups the predictive models to be built.
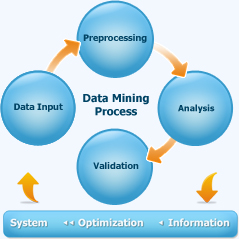
Validation
Next comes building various models and choosing the most relevant ones. This decision is based on their possible predictive performance and of being able to produce stable results across all the samples. Simple as it sounds, to truly get the results, all possible models must be treated with data to simulate scenarios. The model with most stable statistical feature is validated.
Application
Once the relevant models are finalised, the same is applied to new data to understand and predict the estimated outcomes. Application of data models is an ongoing and complex process since every new dataset needs to be configured in the model.
Data Mining and predictive analysis essentially involves blending statistical methodology where the traditional statistics machine learning and complex algorithms. This greatly increases the need for efficient and skilled data handlers. This could include data analysts and scientists.
See how you can become data scientist here:
Data crunchers use data mining and predictive analysis actively to get an edge in the big data management. Database platforms like Hadoop assist in database management and large-scale distribution. But the costs involved in setting up data centres and big data management capacity are high. Budgets allocated within the enterprise are more project-focussed and analytics budgets are usually limited. Quite often, big data and analytics project fail to launch because of this problem! The other problem is that to run effective predictive models, data requires to be handled by scientists with experience. Finding and setting together a technologically-advanced team is a daunting task most enterprises face outside the tech domain.
See how Hadoop helps E-commerce & retail: https://www.promptcloud.com/blog/hadoop-for-ecommerce-and-retail
Predictive Analysis model
A predictive analysis model is essentially predicting the all possible outcomes from a given set of data. Here are a few steps that can be taken to help build and identify the “ideal” predictive analysis model. These steps more or less mirror the usual statistical methodology of building a test model.
Defining an objective
This is the first and a critical step. Unless the objective is identified and defined there can be no concrete results since there wouldn’t be clarity to compare the final outcome to the expected result. It also helps understand the scope of the project.
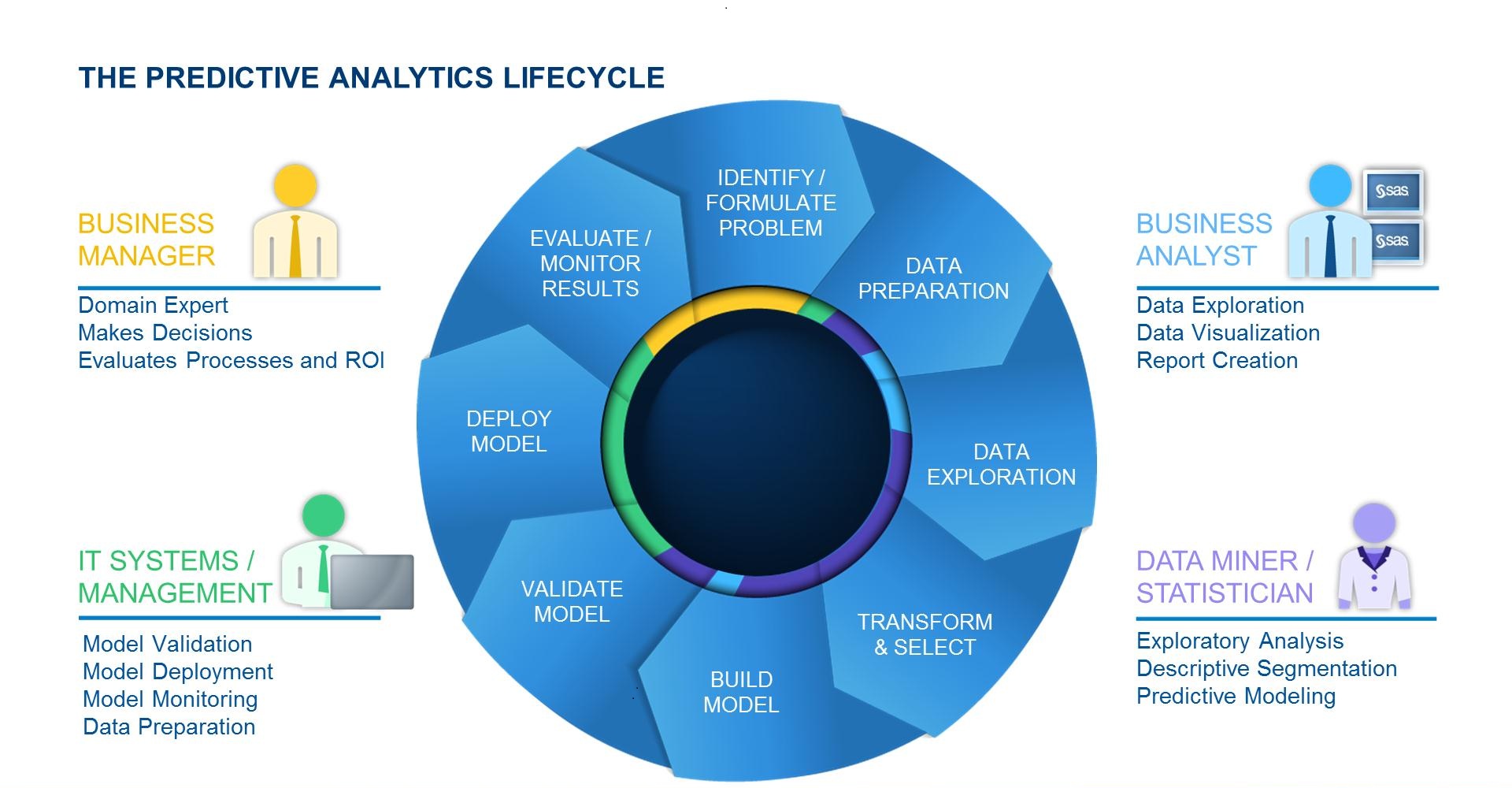
Preparing the data
This is more to do with web data mining. Historic data used for training the model is scattered across multiple platforms and sources. To compound the problem, data can be unstructured with possible duplicate accounts and missing values! Data quality determines the quality of the model, and thus it becomes imperative that data is healthy and relevant.
Data Sampling
Once mined, Data is essentially split into 2 parts. One set is for training that is used to build the model and the second is the ‘test’ set that is used to verify the accuracy of the final output. This also helps identify and filter the noise component.
Model Building
Sampling cam equally result in a single algorithm or parallel & connected algorithms. In such a case the data goes through multiple testing and a decision is based on the final output.
Execution
Once a model gets finalized, the other teams in the organization need to be involved to build a deployable model and understand its impact on the overall business.

Read more about using data in business intelligence.
The possibilities with Data mining & Predictive analysis are huge. It also gives a huge room for learning and experimenting. There are several tools available in the industry to aid through all the steps of data mining and predictive analysis. The combination of human expertise and intellect along with the help of the available tools and the overall cooperation within the multiple channels within the organization essentially ensures a stronger grip on the ability to build a solid predictive model.
When used together, predictive analytics and data mining help marketing professionals anticipate and get ready for customer needs, rather than just reacting to them.
Image Credits : datascienceconsultingtips | blogs.sas | anderson















