


Table of Contents
show
Geographic data is, by far, the single most indispensable entity on which a business stands these days even before standing on brick and mortar.
We have already discussed various use cases that validate the above statement in our older posts on What enterprises do with Big Data series. But here’s a specific use case that deserves undivided attention in lieu of intense research that it facilitates.
Problem
Sometime ago, an enterprise that leverages social media for its research, was discussing their problem of getting hold of large-scale data with us. The objective was catching up with social media feeds in near real-time AND location-wise. Data was intended to be from across the spectrum- news, blogs, reviews, Twitter, etc. A perfect solution was not supposed to compromise on-
- Scale – there had to be roads open for adding as many further sites or feeds to the source list for data acquisition. Scaling down was important too if some sources had lower returns. All this was to be supported dynamically.
- Quality– very low tolerance for noise and a hassle-free consumption of data by their analysts was key to keep up with their client SLA’s.
What did we do to aggregate this geographic data?
The following considerations were taken into account to set up the mass-scale low latency pipeline for these set of requirements.
- Foremost attribute to factor in was the dynamically changing scale of requirements. Our DaaS platform had to first understand how many clusters to allocate in near real-time and then continuously optimize on it.
- The source list was taken through a geo-intelligence API to associate a markup with the crawls. This was to ensure data was aggregated only from countries of interest.
- An alert mechanism was prime that could indicate, out of those half a million odd sources, which ones had gone dormant and which ones were still lush; essentially thereby stitching in time.
- Results from the above step were to be fed into an adaptive crawler that could behave smart by crawling the popular pages more often and be guaranteed of higher volumes.
- These results were to be analyzed for relevant topics or keywords, and then extracted in a structured format- an integral part of our pipeline.
- Dealing with so much data every minute was going to be onerous at the client’s end as well. Hence, the icing on this big data cake had to be a hosted indexing layer to cater to queries. Queries would mostly be predefined and made up of key phrases with certain logical combinations (AND, OR, NOT) that would help the client analyze and focus better.
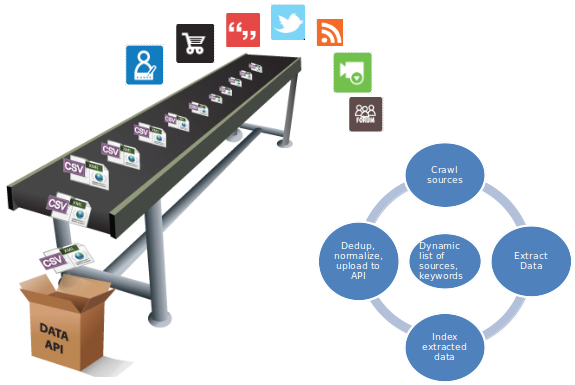
Geo-specific low latency crawls for dynamic list of sources and keywords |
What does our client do with this data?
For a market research firm, such a solution supports a good amount of their portfolio ranging from brand monitoring of major brands and their competitors to sentiment analysis of consumer network.
For the sake of an illustration, let’s say our client is X and Microsoft and Honda are X’s clients. So Microsoft asks X to get all data feeds from US & Canada where both Yahoo! and Google are mentioned together but Microsoft isn’t. We gather data feeds only from US and Canada from a variety of sources and index them for X. X can then search through our index to check the number of such occurrences where Microsoft wasn’t mentioned along with Yahoo! and Google.
https://index.promptcloud.com/A/count?q=(google%20AND%20Yahoo%20)%20NOT%20microsoft
X could also look up the actual articles for such occurrences and provide its analysis to Microsoft.
https://index.promptcloud.com/A/?q=(google%20AND%20Yahoo%20)%20NOT%20microsoft
The most recent geographic data piece could be accessed using a query pattern like-
https://index.promptcloud.com/A/search?q=google%20AND%20yahoo%20&sort=published:desc&size=1
Note- these links are only for illustration.
Benefits
Apart from the obvious escape from the pains inflicted by big data aggregation, there were some real benefits from such a solution.
- results were more focused here as opposed to those from a global index; targeting and segmentation could hence be done in that manner
- in addition to the hosted index, the data API had a bigger pool of geographic data as fallback
- all this structured data was continuously coming from a single source hence avoiding all the synchronization issues
In case you are interested in further details of this offering, give us a shout.















