



Table of Contents
show
In the era of big data, the ability to collect and analyze vast amounts of information is crucial for advancing machine learning (ML) projects. Web scraping offers a powerful solution for gathering structured data from the web, enabling you to train machine learning models more effectively. By the end of this article, you’ll understand how to leverage web scraping machine learning to elevate your data game in 2024.
What is Machine Learning?
Machine learning is a branch of artificial intelligence (AI) focused on developing algorithms that allow computers to learn from and make predictions or decisions based on data. Unlike traditional programming, where explicit instructions are given for every action, machine learning models learn from data to identify patterns and relationships, which they use to make accurate predictions or decisions.
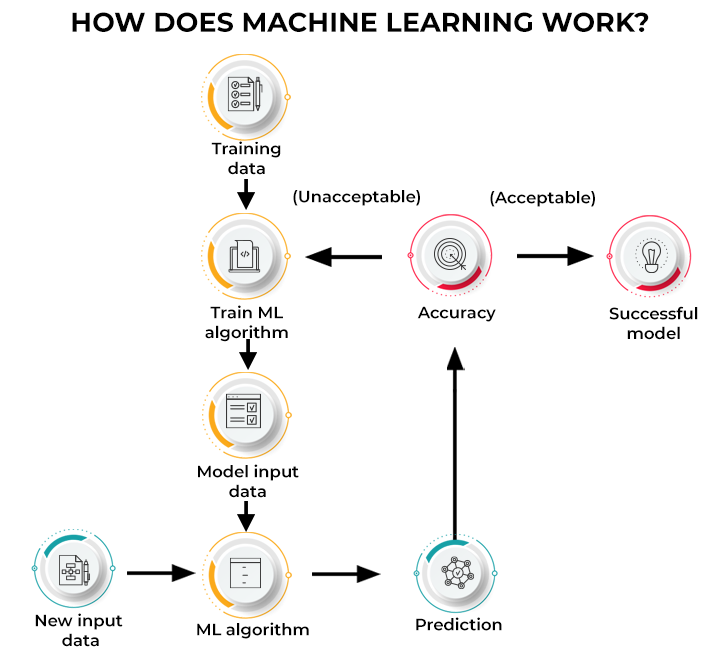
Source: Spiceworks
Machine learning applications span various domains, including healthcare, finance, marketing, and more. These algorithms have revolutionized industries by automating complex tasks, enhancing accuracy, improving efficiency, and uncovering hidden insights from large datasets.
What is the Importance of Web Scraping in Machine Learning?
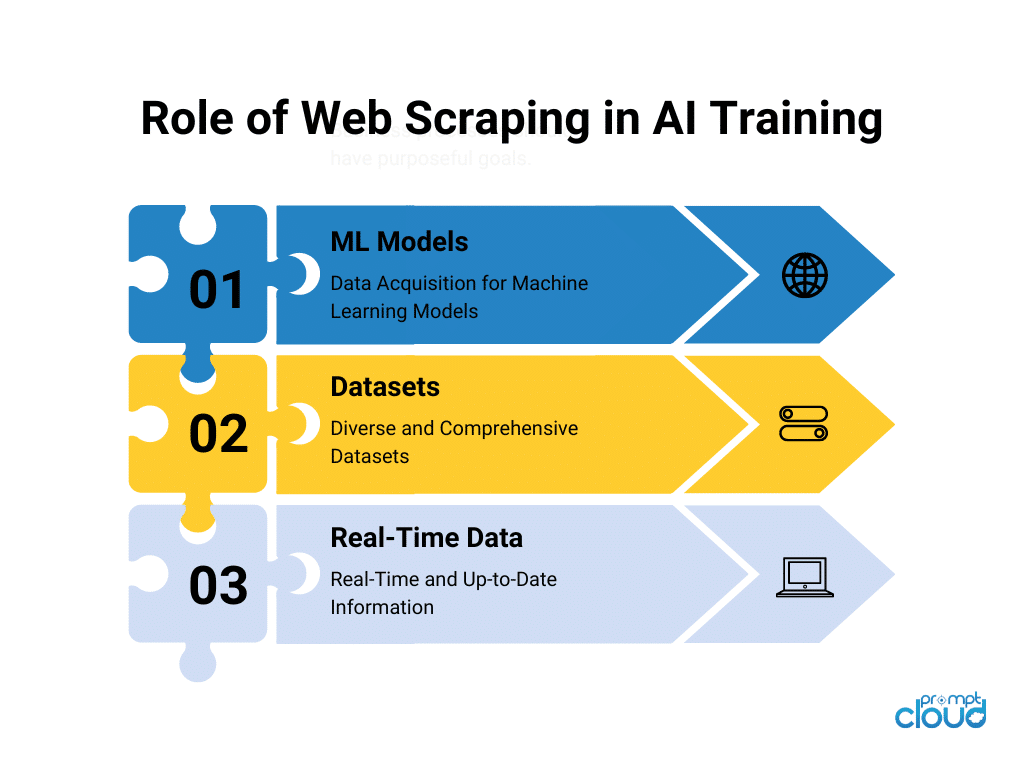
The success of machine learning projects hinges on the quality and quantity of the data available. Without web scraping, acquiring such data would be a labor-intensive, manual process. Additionally, insufficient or outdated data can lead to inaccurate predictions and suboptimal insights from your models.
Web scraping allows access to data that is not readily available through traditional means. This includes user-generated content, product reviews, social media data, news articles, and more. By scraping websites, researchers and businesses can gather diverse datasets that drive innovation and discovery.
A robust dataset obtained through web scraping machine learning can train models to recognize patterns, make predictions, and derive valuable insights. Whether you’re developing a recommendation system, sentiment analysis tool, or fraud detection algorithm, web scraping provides the essential data foundation for success.
Moreover, web scraping machine learning enables the continuous updating of models with the latest information. Regularly scraping websites ensures your models are trained on current data, allowing them to adapt and provide accurate predictions even in a rapidly changing environment.
How Is Scraped Data Used In Machine Learning?
Scraped data serves as a fundamental resource for a wide array of machine learning applications. Here are some key uses of scraped data in machine learning:
Training Data for Models
Scraped data provides the extensive datasets required to train machine learning models effectively. High-quality and diverse training data help models learn better patterns, relationships, and features, leading to improved accuracy and performance.
Sentiment Analysis
By scraping data from social media platforms, review sites, and forums, businesses can perform sentiment analysis. This involves analyzing user opinions and emotions towards products, services, or brands, helping companies understand customer satisfaction and make informed decisions.
Recommendation Systems
E-commerce platforms and content providers can use scraped data on user behavior, preferences, and interactions to build recommendation systems. These systems suggest products, services, or content tailored to individual users, enhancing user experience and engagement.
Market and Competitor Analysis
Scraped data from competitor websites, pricing databases, and market trends provide valuable insights for market analysis. Businesses can track competitor pricing, product availability, and promotional strategies to stay competitive and adapt their own strategies accordingly.
Fraud Detection
Financial institutions and online platforms can use scraped data to detect fraudulent activities. By analyzing patterns and anomalies in transaction data, user behavior, and other relevant information, machine learning models can identify and prevent fraud more effectively.
Predictive Analytics
Scraped data is essential for predictive analytics, where machine learning models forecast future trends, behaviors, and outcomes. For example, businesses can predict sales, customer churn, or inventory needs based on historical data and current trends.
Natural Language Processing (NLP)
NLP applications, such as chatbots, language translation, and text summarization, rely on large text datasets. Scraped data from websites, articles, and social media provide the textual information needed to train and refine NLP models.
Healthcare Analytics
In the healthcare sector, scraped data from medical publications, patient reviews, and clinical trial reports can be used to train models for disease prediction, treatment recommendation, and patient care optimization. This helps in improving patient outcomes and advancing medical research.
Future Trends and Innovations in Web Scraping Machine Learning
As technology advances, the synergy between web scraping and machine learning continues to evolve, opening up new possibilities and driving innovation. Here are some key future trends and innovations in web scraping machine learning:
Advanced Anti-Detection Techniques
As websites become more adept at detecting and blocking web scraping activities, the development of advanced anti-detection techniques will be crucial. Future web scrapers will incorporate sophisticated methods like mimicking human behavior more accurately, using AI to predict and avoid detection mechanisms, and employing advanced proxy rotation strategies to bypass IP bans.
AI-Powered Web Scraping
Artificial intelligence will play a significant role in enhancing web scraping machine learning. AI-powered scrapers will be able to adapt to changes in website structures automatically, reducing the need for manual updates. Machine learning algorithms can be used to optimize scraping strategies, improve data extraction accuracy, and predict potential issues before they arise.
Real-Time Data Extraction
The demand for real-time data will continue to grow, driving the need for web scrapers that can extract and process data instantaneously. Innovations in web scraping technology will focus on achieving lower latency and higher speed, enabling businesses to access and analyze data as it becomes available.
Integration with Big Data Technologies
Web scraping will increasingly integrate with big data technologies such as Hadoop and Spark. This integration will allow for the efficient handling and processing of large volumes of scraped data, facilitating deeper insights and more complex machine learning models. Seamless integration with data lakes and cloud storage solutions will also enhance data accessibility and management.
Improved Natural Language Processing (NLP)
Web scraping will benefit from advancements in natural language processing, enabling more accurate extraction of unstructured data from textual sources. Enhanced NLP capabilities will allow scrapers to understand context, sentiment, and semantic relationships within the data, improving the quality of information fed into machine learning models.
Enhanced Data Quality and Cleaning
Future web scrapers will come equipped with built-in data cleaning and quality assurance features. These tools will automatically detect and correct inconsistencies, handle missing values, and normalize data formats, ensuring that the scraped data is ready for immediate use in machine learning applications.
Customizable and Scalable Solutions
As the demand for customized and scalable scraping solutions increases, future innovations will focus on providing highly customizable tools that can be tailored to specific business needs. Scalable scraping infrastructure will support large-scale data collection efforts, accommodating the growing data requirements of machine learning projects.
Cross-Platform and Multi-Source Scraping
Innovations will enable seamless scraping across multiple platforms and data sources, integrating information from websites, social media, APIs, and more. Cross-platform scraping will provide a more comprehensive view of the data landscape, enriching machine learning models with diverse and multifaceted datasets.
User-Friendly Interfaces & Automation
The future of web scraping will see the development of more user-friendly interfaces and automation capabilities. These tools will allow users with limited technical expertise to set up and manage web scraping projects easily. Automated workflows and scheduling will enable continuous data collection without the need for constant manual intervention.
Conclusion
The future of web scraping for machine learning is poised for significant advancements, driven by innovations in AI, real-time data processing, ethical practices, and enhanced integration with big data technologies. By staying abreast of these trends and adopting cutting-edge scraping solutions, businesses can unlock new opportunities and drive their machine learning projects to greater heights.
Ready to embrace the future of web scraping? Contact us today to discover how our advanced web scraping solutions can help you stay ahead of the curve and leverage the latest trends and innovations for your machine learning needs.














