



Table of Contents
show
Web scraping has become an essential skill for developers, data analysts, and businesses looking to extract information from websites. With the rise of e-commerce, quick commerce, and dynamic web applications, extracting structured data from web pages has become a valuable tool for competitive analysis, market research, and automation.
One of the best tools for this job is Puppeteer, a Node.js library that provides a high-level API to control headless Chrome browsers. Unlike traditional scraping methods that struggle with JavaScript-heavy websites, Puppeteer can interact with pages just like a real user, allowing developers to scrape dynamic content, automate tasks, and even perform UI testing.
If you’re looking to scrape dynamic websites – especially those built with JavaScript frameworks – Puppeteer web scraping is a fantastic option. Whether you need to extract product listings, monitor price changes, or analyze inventory levels, Puppeteer provides the flexibility to automate interactions such as clicking buttons, scrolling, and navigating paginated content.
What to Expect from This Puppeteer Web Scraping Guide?
In this guide, we’ll walk through the process of Puppeteer web scraping, with an example of scraping a quick commerce website, specifically Blinkit (formerly Grofers), a popular instant grocery delivery service. We will extract product listings, including names, prices, availability, and ratings, and handle pagination efficiently. By the end of this tutorial, you’ll have a solid understanding of how to use Puppeteer to extract and process data from web pages, enabling you to apply these skills to various scraping projects.
What is Puppeteer?
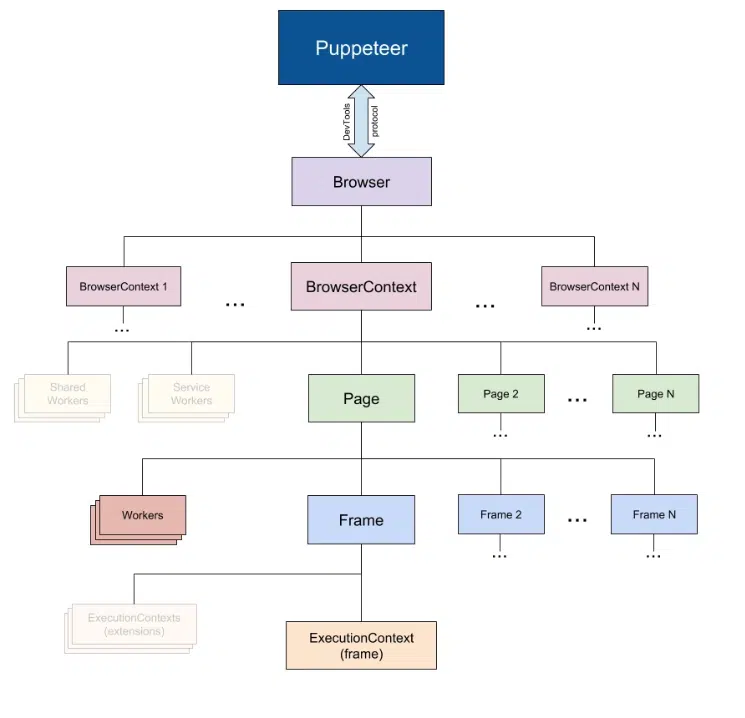
Source: research.aimultiple
Puppeteer is a Node.js library developed by Google that allows you to automate browser interactions. Unlike traditional web scraping libraries like BeautifulSoup (which only handles static HTML), Puppeteer can render JavaScript-heavy content, making it perfect for scraping modern web applications.
Puppeteer provides a headless Chrome browser that allows developers to interact with web pages programmatically. It can be used not only for Puppeteer web scraping but also for automated testing, website performance analysis, and generating pre-rendered content for SEO optimization.
Top Features of Puppeteer for Web Scraping
- Full Browser Automation: Puppeteer can interact with web pages just like a real user, including clicking buttons, filling forms, and scrolling.
- JavaScript Execution: Many modern websites rely heavily on JavaScript. Unlike traditional scrapers, Puppeteer can execute JavaScript and wait for elements to load before extracting data.
- Network Throttling: You can simulate different network conditions to test how a page loads under various scenarios.
- Intercept and Modify Requests: Puppeteer allows you to block ads, bypass paywalls, or inject custom scripts to alter page behavior.
- Automated Screenshots and PDFs: You can take screenshots of web pages for visual verification or reporting, and generate PDFs of website content.
- Simulate User Behavior: Puppeteer supports mouse movements, keyboard inputs, and even touch gestures, making it useful for UI automation.
- Support for Both Headless and Headed Modes: Run Puppeteer in headless mode for fast, background automation, or in headed mode to visually debug scraping processes.
Why Use Puppeteer for Web Scraping?
Web scraping can be challenging due to modern websites employing JavaScript frameworks, lazy loading, CAPTCHAs, and anti-bot mechanisms. Puppeteer provides several advantages that make it a powerful scraping tool.
Key Advantages of Using Puppeteer for Web Scraping
- Handles JavaScript-Rendered Content: Many websites today use React, Vue.js, or Angular, which rely on JavaScript to load content dynamically. Puppeteer ensures all elements are fully loaded before extracting data.
- Headless Browser Execution: You can run Puppeteer in headless mode, meaning it operates in the background without a visible browser window, increasing performance and efficiency.
- Automates User Interactions: Need to click a button, log in, or navigate through pages? Puppeteer can handle all of these actions seamlessly.
- Screenshots and Debugging: Take screenshots of the entire webpage or specific elements to verify that scraping is capturing the correct data.
- Customizable Page Waits and Timers: Puppeteer allows you to wait for elements to appear before proceeding, making it more reliable than traditional scrapers.
- Bypass Basic Bot Detection: Many websites implement basic bot protection techniques. By mimicking real browser behavior, Puppeteer can reduce the chances of being blocked.
- Built-in Request Interception: Puppeteer allows you to modify network requests, block ads, or even load specific content without unnecessary clutter.
- Supports Cloud Deployment: Puppeteer scripts can run on cloud services such as AWS Lambda, Google Cloud Functions, or Heroku, enabling large-scale scraping operations.
Puppeteer Setup: Guide to Scraping Blinkit for Product Listings
Before we begin scraping, we need to set up Puppeteer. Make sure you have Node.js installed on your system.
1. Install Puppeteer
Run the following command in your terminal to install Puppeteer:
npm install puppeteer
This will download Chromium and the Puppeteer library.
2. Create a New JavaScript File
Create a new file, blinkit_scraper.js, and open it in your code editor.
For this example, let’s say we want to scrape Blinkit to extract product names, prices, ratings, and availability.
3. Launch a Puppeteer Browser
In blinkit_scraper.js, start by launching a Puppeteer-controlled browser:
const puppeteer = require(‘puppeteer’);
(async () => {
const browser = await puppeteer.launch({ headless: true }); // Run headless mode
const page = await browser.newPage();
await page.goto(‘https://blinkit.com’, { waitUntil: ‘networkidle2’ });
console.log(‘Blinkit homepage loaded!’);
await browser.close();
})();
4. Selecting Elements and Extracting Data
Now, let’s extract product details such as name, price, rating, and availability. Inspect the Blinkit website using the browser’s developer tools (F12 or Ctrl + Shift + I) to find the correct selectors.
Let’s assume the HTML structure looks like this:
<div class=”product-card”>
<h2 class=”product-title”>Fresh Bananas</h2>
<span class=”product-price”>₹49</span>
<span class=”product-rating”>4.5</span>
<span class=”availability”>In Stock</span>
</div>
We will use Puppeteer’s evaluate method to extract this information.
const puppeteer = require(‘puppeteer’);
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto(‘https://blinkit.com/s/vegetables-fruits’, { waitUntil: ‘networkidle2’ });
const products = await page.evaluate(() => {
let items = [];
document.querySelectorAll(‘.product-card’).forEach(product => {
let name = product.querySelector(‘.product-title’)?.innerText;
let price = product.querySelector(‘.product-price’)?.innerText;
let rating = product.querySelector(‘.product-rating’)?.innerText;
let availability = product.querySelector(‘.availability’)?.innerText;
items.push({ name, price, rating, availability });
});
return items;
});
console.log(products);
await browser.close();
})();
5. Handling Pagination
If the website has multiple pages, you may need to navigate through them. You can click the “Next” button until all products are scraped.
while (await page.$(‘.next-page-button’) !== null) {
await page.click(‘.next-page-button’);
await page.waitForTimeout(3000); // Wait for new products to load
// Extract data again
}
Top Use Cases of Blinkit Web Scraping for E-commerce Insights
Puppeteer web scraping Blinkit can be useful for various applications, including:
- Competitive Pricing Analysis: Compare Blinkit’s product prices with other quick commerce platforms like Instacart, BigBasket, or Swiggy Instamart.
- Demand Prediction: Track product availability to predict demand trends and shortages in real-time.
- Market Research for FMCG Brands: Monitor product ratings and reviews to understand customer preferences and product performance.
- Automated Inventory Tracking: Create an automated dashboard that alerts retailers when certain items go out of stock.
- Personal Price Tracker: Build a price tracker that alerts users when their favorite groceries become cheaper.
Best Practices for Puppeteer Web Scraping
1. Respect Robots.txt and Terms of Service
Before scraping Blinkit, check its robots.txt file (https://blinkit.com/robots.txt) to see if scraping is allowed.
2. Use User Agents and Headers
Many websites block bots. You can mimic a real user by setting a user agent:
await page.setUserAgent(‘Mozilla/5.0 (Windows NT 10.0; Win64; x64)’);
3. Implement Delays and Randomization
To avoid being detected, introduce random delays:
await page.waitForTimeout(Math.floor(Math.random() * 5000) + 2000);
4. Use Proxy Servers
If a website blocks your IP, consider using proxies.
5. Save Data to a File
Instead of printing data to the console, save it to a JSON file:
const fs = require(‘fs’);
fs.writeFileSync(‘blinkit_products.json’, JSON.stringify(products, null, 2));
Conclusion
Puppeteer is a powerful tool for web scraping, especially for JavaScript-heavy websites like Blinkit. In this guide, we learned how to:
- Set up Puppeteer
- Navigate to Blinkit and extract product data
- Handle pagination
- Implement best practices to avoid getting blocked
With this knowledge, you can build a web scraper tailored for competitive analysis, market research, or personal tracking. Just remember to always respect the website’s terms of service and avoid excessive requests. For any custom web scraping requirements, get in touch with us at sales@promptcloud.com















