



Table of Contents
show
In the era of big data, the ability to extract useful information from the web has become a vital skill. Web scraping is the process of programmatically collecting data from websites, and R – a powerful language widely used for data analysis and statistical computing, offers robust tools for this task. Whether you are a data analyst, researcher, or enthusiast, web scraping with R can help you gather valuable data from across the web to fuel your projects.
What is Web Scraping? and Why It’s Important?
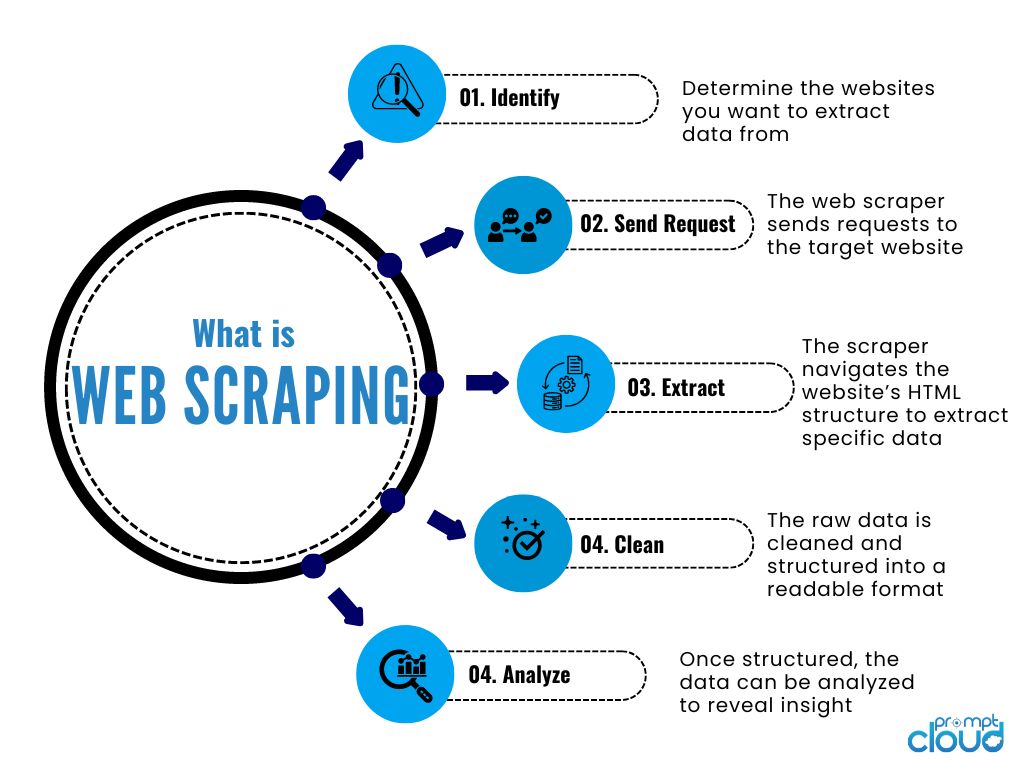
Web scraping is used to collect large amounts of data that are otherwise inaccessible through APIs or downloadable datasets. With R, this process becomes streamlined and efficient, allowing users to scrape data such as product prices, news articles, financial information, and more. The rvest package in R, for instance, simplifies the process by providing functions that mimic the actions of a web browser, such as reading HTML content, selecting specific elements, and parsing the desired data. These capabilities make R an excellent choice for automating data collection tasks and building datasets that can inform decision-making processes.
Top Tools and Libraries for Web Scraping in R
To get started with web scraping in R, you’ll primarily rely on the rvest package, which is specifically designed for scraping web content. Other essential packages include httr for handling HTTP requests, xml2 for parsing XML and HTML, and dplyr for data manipulation once the data is scraped. The rvest package works by allowing you to easily read a webpage’s HTML content and use CSS selectors or XPath queries to target the specific data elements you need. Additionally, the RSelenium package can be employed for more complex scraping tasks that require JavaScript rendering or interacting with web elements like buttons or forms.
Beginner’s Guide to R Programming for Web Scraping
Before diving into web scraping with R, it’s essential to have a solid foundation in R programming. R is a versatile language that is widely used in data analysis, statistical modeling, and data visualization. To get started with R programming, follow these easy steps:
- Install R: Download and install R from the Comprehensive R Archive Network (CRAN).
- Select the appropriate version for your operating system (Windows, macOS, or Linux).
- Select an IDE: Choose an Integrated Development Environment (IDE) to work with R effortlessly. RStudio is a popular choice, providing a user-friendly interface and a range of useful features.
With R and an IDE in place, you’re ready to explore the world of R programming. Here are some key concepts you should familiarize yourself with:
- Data structures: R offers several data structures, including vectors, matrices, data frames, and lists. These structures help you organize and manipulate data effectively.
- Control structures: Understand the basic control structures in R, such as if-else statements, for loops, and while loops, to control the flow of your code.
- Functions: Learn how to write and use functions to simplify repetitive tasks, improve code readability, and enhance reusability.
Once you are comfortable with the basics, it’s time to expand your skillset and learn about web scraping in R. The following packages are essential for web scraping with R:
- rvest: A popular package for web scraping. It enables you to extract data from websites easily and efficiently.
- httr: Designed for working with HTTP, this package is useful for managing web connections and handling API requests.
- xml2: Useful for parsing XML and HTML content, the xml2 package helps in navigating and extracting data from webpages.
Lastly, it’s a great idea to familiarize yourself with some common web scraping tasks, such as:
- Logging into a website
- Navigating pagination
- Scraping and cleaning data
- Writing data to files
By understanding the fundamentals of R programming and mastering essential web scraping packages, you’ll be well-prepared to tackle any web scraping project with R.
Fundamentals of Web Scraping
Before diving into web scraping with R, it’s essential to have a solid understanding of the basics. After all, web scraping is a highly versatile and powerful tool, particularly when combined with the analytical capabilities of R. So, let’s break down the fundamentals and get you on your way to becoming an expert web scraper.
First and foremost, web scraping is the process of extracting data from websites. You’ll typically use specific tools or write scripts to automate the retrieval of information from web pages. In R, popular web scraping packages include rvest and xml2, which make it easier to navigate, parse, and manipulate HTML and XML documents.
To ensure effective web scraping, you must focus on a few essential steps:
- Identifying the target web page(s): You’ll need to know where to begin searching for data.
- Inspecting the web page structure: Understanding the structure of a web page is crucial, as it will help you zero in on the data you’re looking to extract.
- Constructing your web scraper: With your target page and specific elements identified, you can turn to R to create your web scraper.
- Storing the extracted data: Once you’ve successfully scraped your data, you’ll need to store it for analysis. R offers various options for storage
While web scraping might seem intimidating at first, breaking it down into these essential steps will simplify the process, making it more manageable. Keep in mind that when web scraping, it’s important to be respectful of website owners’ terms of service and their robots.txt files. They likely put effort into creating their content, and scraping without permission may infringe on their copyright. Additionally, excessive scraping can burden a site’s server, so be mindful not to overload the web pages you’re targeting.
With these fundamentals in mind, you’re now ready to embark on your web scraping journey with R. So go ahead and put these principles into practice, and watch as endless data possibilities.
Installing & Loading Essential R Libraries
It’s crucial to have the necessary libraries installed and loaded. In this section, we’ll guide you through the installation and setup of the most important packages for web scraping. By the end of this section, you’ll be equipped with the essential tools to begin your web scraping journey in R.
- Rvest
The rvest package is R’s go-to library for web scraping. It simplifies the process by providing an intuitive set of functions to extract and manipulate HTML content. To install and load rvest in your R environment, follow these steps:
- Install the package with the command: install.packages(“rvest”)
- Load the package: library(rvest)
- httr
The httr package is another essential tool for working with HTTP requests and web APIs. This library allows you to send requests, handle responses, and streamline advanced web interactions. Here’s how to install and load httr:
- Install the package: install.packages(“httr”)
- Load the package: library(httr)
SelectorGadget
SelectorGadget isn’t a package, but rather a handy browser extension used to identify and extract the correct CSS selectors with ease. It’s essential for efficient web scraping in R.
In addition to the aforementioned libraries and tools, consider the following packages for handling specific web data formats:
- XML: To parse and manipulate XML data, use the xml2 package.
- JSON: For dealing with JSON data, turn to the jsonlite package.
- HTML Tables: When working with HTML tables, the htmlTable package can be a lifesaver.
By installing and loading these essential R libraries, you’ll be well-prepared to tackle web scraping projects in R effectively. Equip yourself with these powerful tools, and you’ll be scraping data like a pro in no time!
How to Identify Your Data Target for Web Scraping?
To make the most of web scraping in R, it’s crucial to first identify your data target. This ensures you’re extracting the right information and avoid wasting resources on unnecessary data. Here are a few pointers on how to identify your ideal data target:
- Define your objective: Before diving into web scraping, determine what kind of data you’re after.
- Research potential websites: Once you have a clear idea of the data you need, you can start exploring websites that host the desired information. Focus on websites with well-structured content, making it easier to scrape and navigate through.
- Check for available APIs: Sometimes, websites offer APIs (Application Programming Interfaces) that facilitate easy access to their data. If the website you’re targeting has an API, it’s best to use that instead of web scraping to ensure a more efficient and accurate data extraction process.
- Consider legal and ethical aspects: Although web scraping has its fair share of benefits, it’s essential to be mindful of the legalities and ethical issues involved.
If you’ve successfully completed these steps, you’re now ready to proceed with the actual web scraping process.
- Install and load rvest: First, you’ll need to install the package with the install.packages(“rvest”) command, and then load it by typing library(rvest).
- Read the website: Using the read_html() function, input the URL of the website you want to scrape.
- Select the desired elements: Identify the HTML elements containing the information you need by inspecting the website’s source code. Utilize the html_nodes() function to target these specific elements.
- Extract the data: With the html_text() or html_attr() functions, extract the text or desired attribute from the selected elements.
Once you have your data extracted, you can further process and analyze it to fulfill your objectives. Web scraping in R opens up a world of possibilities, granting access to a vast array of data that may not be readily accessible otherwise.
How to Extract Information Using Rvest?
Diving into the world of web scraping, Rvest is a go-to package for extracting information from websites using R. This popular package simplifies the process by handling the underlying complexities. Let’s explore its capabilities and how you can use it to your advantage.
To get started with Rvest, you’ll need to install and load it in your R environment. With Rvest installed, you can begin extracting information from websites by following these straightforward steps:
- Read the web page with read_html() function, which takes the URL as its input.
- Identify and select the contents you want to extract using the html_nodes() function along with CSS selectors or XPath queries.
- Obtain the desired data from the selected contents using html_text() or other functions.
Error Handling
Web scraping can sometimes encounter errors or missing data. To handle such situations, Rvest provides handy functions like html_node() for extracting single content and html_text2() which helps in preserving whitespace.
Rvest is a powerful and easy-to-use package for web scraping with R. By following these steps, you can extract valuable information from websites and use it for your data analysis projects.
Data Cleaning & Preprocessing
When you start web scraping in R, one of the crucial steps is data cleaning and preprocessing. In this section, you’ll learn how to handle missing values, remove duplicates, and format data to make the information more digestible.
Handling Missing Values
Web scraping may yield incomplete data due to inconsistencies in the source website structure or temporary unresponsiveness. You can tackle this problem by:
- Replacing missing values with a default value or the mean/median/mode of available data
- Omitting rows with missing values, which is advisable if the missing data percentage is low
- Using advanced methods, such as K-Nearest Neighbors (KNN) or Multiple Imputation by Chained Equations (MICE), to fill in missing values
Removing Duplicates
Duplicate entries can arise from inconsistent scraping or if the source website itself exhibits errors. To ensure data quality, consider:
- Identifying and removing exact duplicates with the duplicated() and unique() functions
- Employing the stringdist package to compare similarity between strings and handle near-duplicates
Formatting Data
Properly formatting your data helps with readability and further analysis. Here are a few techniques to consider:
- Converting date and time formats into unified standards, such as YYYY-MM-DD for dates and HH:MM:SS for times
- Ensuring consistency in numerical data, for example, always using a comma or dot to separate thousands
- Standardizing the case of text data to lowercase or uppercase, which helps with text analysis and string searches
- Splitting combined data fields, such as online addresses with a street name and city, into separate columns for easier analysis
By taking the time to clean and preprocess your data, you’ll ensure accurate and meaningful analysis results.
Conclusion
Using the right tools and an organized approach, web scraping in R can help you make use of the vast amount of data available on the internet. But don’t forget to follow moral guidelines, honor website policies, and be aware of any applicable laws. For any custom web scraping requirements, get in touch with us at sales@promptcloud.com



































