



Table of Contents
show
When it comes to alternative data sources, Twitter is the gold mine of social media data. While multiple social media platforms have gained mass popularity, some nuances of Twitter make it the most favored among companies and individuals who want to use social media data to build predictive models and extract information. You can use old Tweets for your analysis or even fetch Tweets in real-time for your study. PromptCloud takes a look at how we can analyze Twitter for the US Presidential Election trends online.
All tweets are limited to 280 characters (it was 140 earlier), and this helps sentiment analysis algorithms digest the text better. Another plus point is that everything on Twitter is in the form of Tweets. There’s no other format in which data can exist on the website. Brands are using Twitter to find mentions and understand the public perception of them. Elections are being fought first on Twitter and then on the ground. Nations are complaining against each other here.
Governments are making announcements on Twitter, and anyone can check the trending topics to find the pulse of the public. This year’s US Presidential Election started playing out on social media long before the public debates even started, and that is why we will be using Twitter data to gauge the public perception of both the candidates.
What is Sentiment Analysis and Why is it Important?
Sentiment analysis is an automated process through which text data is analyzed and then classified based on the opinions expressed by the people, into three categories- positive, neutral, or negative. According to a 2019 report, Twitter witnessed dramatic growth and now has nearly 300 million active users. Thus, it has become one of the prime spots for monitoring the sentiments of people, and in this case, voters. Through the use of Natural Language Processing (NLP), human language is first tokenized and normalized after which it can be made sense of programmatically. Sentiment analysis tools can sort through the data from Twitter automatically and thus, results are fast and can be obtained in real-time. There are many other advantages to using Twitter data:
- Large scale unstructured data from Twitter can be analyzed easily without manual handling
- Any changes or shifts in moods of the voters can be detected instantly
- With the use of a trained machine learning model, you can use just one set of rules on your data so that there are no inconsistencies
Twitter and the US Presidential Election
Social Media platforms like Twitter being the most popular platform where people come in to vent their political opinions, has integrated itself with elections for a long time. Twitter now has labels for US election candidates, which help the public know which offices they are running for. One of the major fights of the last US presidential election was on Twitter, and there are multiple studies and research articles on the tweets of both candidates, sentiments of tweets by voters, and more. There have even been studies, where people could be predicted as Republican or Democrat based on their tweets.

The presidential candidates have been seen to attack each other, comment on important events, and even reply to their opponents, all on Twitter. In response, the public reacts to each tweet of these candidates, and voice out their opinion. All this data can be analyzed to understand the support base that each is commanding. In fact, instead of creating a separate survey and asking people for their opinion to predict the election results, using data from a website like Twitter can provide far more accurate results.
How can you fetch Tweets for Analyzing Twitter Trends?
Now let’s say you want to write your DIY code and test the waters. You can do so by fetching tweets from Twitter in real-time and performing sentiment analysis. In this demo, however, I will be getting the last n number of tweets instead of streaming tweets in real-time. Let’s go over what we will be doing, step by step-
- We will fetch all the tweets where either presidential candidates are mentioned from the first 100 pages of our feed. Since the number of mentions may not be the same, we will be taking the lower count and using the same number of tweets for both candidates in our sentiment analysis later on. We will be saving these tweets in JSON files.
- We will be fetching the last 3200 (approx) tweets of both the presidential candidates and saving them in CSV files.
- The JSON and CSVs that we created earlier using data fetched from Twitter to reach a predictive conclusion.
Step 1
We will be using Tweepy to fetch all the tweets in the first 100 pages of our feed where “Trump” or “Biden” is mentioned. And save these tweets to a JSON file. As usual, you will be needing Python (3.7 or higher preferred), a text editor like Atom, and the Tweepy library. You will also need Twitter dev credentials. For the Twitter developer credentials, you can follow any of the related articles online, such as this one. You will need these 4 keys before you can run any API on Twitter:
- Consumer_key
- Consumer_secret
- Access_key
- Access_secret
Once you have your requirements set up, you can go ahead and run the code below-
We read our credentials from a JSON file so that it is not exposed, and then authenticate the Twitter API. When creating the Twitter API, remember to add “wait_on_rate_limit=True” which is a new feature. What this does is, if you have finished your limit for fetching tweets, it waits until your limits are replenished. Twitter usually defines rate limits that consist of 15-minute intervals.
Once this is done, we create a Tweepy cursor and fetch all the tweets in the last 100 pages of our feed. We do this twice. Once we do it for the search keyword “Trump” and the next time we do it for “Biden”. We save an array of tweets for each candidate. Each array contains multiple dicts with these 3 attributes- the text in the tweet, the time when it was created, and the name of the author. Each block in the array will look something like this:

Step 2
Next, we will be running a code that will fetch around 3200 latest tweets for the Twitter handles- “JoeBiden” and “realDonaldTrump”. We are limited to 3200 tweets due to developer API restrictions. Also, we will be downloading the tweets in batches of 200. Using another Tweepy API, we will be fetching all the tweets of the respective handles.
We will be extracting these attributes for all the tweets:
- Id
- Created_at
- Favorite_count
- Retweet_count
- Text
While we are not using all the attributes that we get in this demo, you can write your DIY code to utilize other attributes. We will be saving the data that we get using this code into CSV files. When you run the code, you will see an output like this in the terminal-
Twitter-Data-Extraction (master) $ python Twitter-scraper.py
For JoeBiden –
…200 tweets have been downloaded so far
…400 tweets have been downloaded so far
…600 tweets have been downloaded so far
…800 tweets have been downloaded so far
This will repeat for both candidates, as the API is called multiple times to fetch all the tweets (around 3200) for both.
Step 3
This is the step where we perform our analytics. We will use all the data that we fetched previously to generate a meaningful graph or chart and showcase our findings. We use the TextBlob library for Python to conduct a sentiment analysis of each tweet with a mention of either candidate. Before we pass each tweet into the TextBlob analyzer, we use a clean_tweet function to remove all special characters that are in the tweet to make our findings better. TextBlob returns a score between 1 and -1 after analyzing its sentiment.
Here 1 stands for very positive whereas -1 stands for very negative. For all tweets with a score >0, we shall take it as a positive tweet. Those with a score equal to 0 shall be counted as neutral while others with a negative score counted as negative. We use these counts for each candidate to compare the public sentiment for each. To make the data and findings more interesting. We also compare the average retweets and favorite hits for the tweets of each candidate.
Once you run the code above, you will see the bar chart below being generated. After fetching all this data, we finally generated some interesting information which we will be discussing next. For creating the graph, we will be using the Matplotlib library of Python and its generic code to create multi-bar graphs.
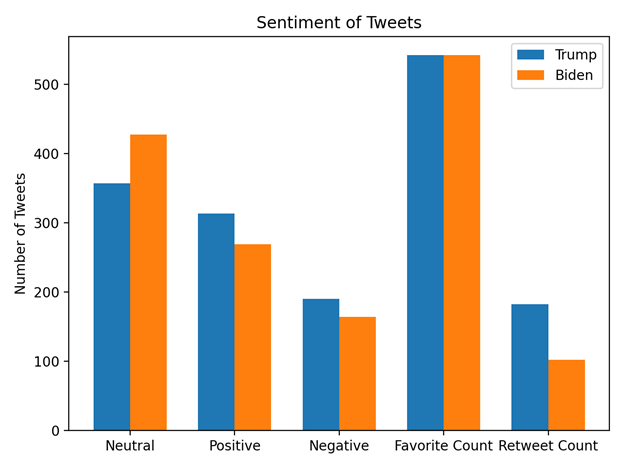
The Findings of the Sentiment Analysis on Twitter of the US Presidential Election
What does our data say? That is always the question, and now we have an answer to it. We can see that the number of neutral tweets for Biden is comparatively higher, whereas both positive and negative tweets are much higher for Trump. This in general can mean that Trump evokes strong feelings among his followers as compared to Biden. As for the favorite count, we can see that both candidates have almost similar averages. Whereas the retweets for Trump are almost double. One thing to note is that to make the graph look normalized. We have divided both favorites and retweets by 100 since only the comparison matters here and not the actual count.
Does this information show who has a higher chance of winning the Presidential Elections? No. But why is that? We fetched tweets and performed sentiment analysis, then why cannot we be certain of our findings. There are many reasons for this, such as we haven’t tested the correctness of our sentiment predicting algorithm and we are not aware of how many retweets were positive comments or negative comments.
However, the most important reason is that our data set is very small. To predict such a massive event, we will need to set up a real-time tweet-fetcher. We will also need to create our own NLP based model that can analyze tweets and sort them based on sentiment. When we go further and analyze all the comments in the retweets for each candidate. We can do all this and more leveraging Python and the available libraries to predict the outcome of the US presidential election.
Conclusion
In case you are looking to fetch real-time data from social media websites like Twitter, a DaaS provider like our team at PromptCloud can help you with your requirements so that you can concentrate on the research or the business side of things. We offer both Social Media Scraping Services as well as the scraping of data from Twitter for sentiment analysis. We provide an end to end solution where you provide us with the requirements, and we provide you with the data in a plug and play format.
If you liked the content above, we think you might enjoy reading Twitter Scraping for Sentiment Analysis for more insights on the topic. If you have anything in your mind please leave us your valuable feedback in the comments section below.















