



Table of Contents
show
Businesses today are increasingly relying on web scraping to extract valuable insights from the vast amount of information available online. Scrapy, a powerful and open-source Python framework, is one of the most popular tools for web scraping due to its flexibility, scalability, and ease of use. Whether you’re scraping product data from eCommerce websites, monitoring competitor pricing, or gathering job listings, Scrapy makes the process efficient and manageable.
In this guide, we’ll walk you through how to create a scrapy web scraping project, covering everything from installation to building a spider, customizing the crawl, and handling common challenges. While Scrapy is a great tool for developers, businesses looking for a fully managed solution might find it easier to work with a partner like PromptCloud.
Let’s dive in!
What is Scrapy?
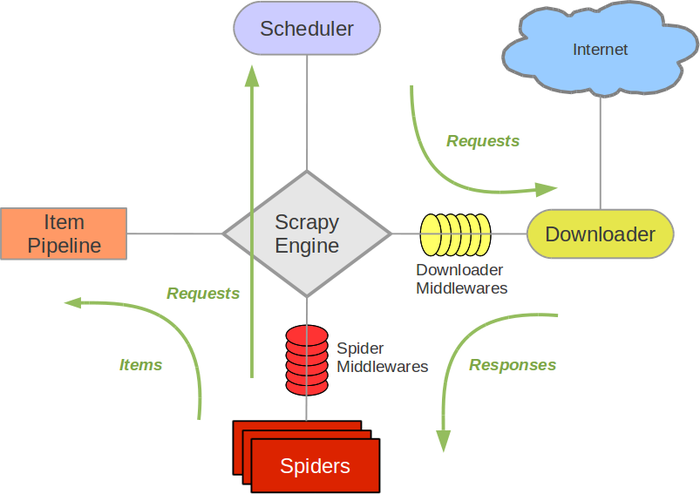
Image Source: Scrapy
Scrapy is a fast, high-level web scraping framework designed for extracting data from websites and processing it according to your needs. It handles requests, follows links, and parses data, making it the go-to solution for developers looking for a scalable web scraping tool.
With Scrapy, you can:
- Build web crawlers (also known as spiders) to scrape large volumes of data.
- Automate data extraction from structured and unstructured web pages.
- Process and store data in various formats like JSON, CSV, or databases.
Why Use Scrapy for Web Scraping?

Image Source: Oxylabs
Web scraping with Scrapy offers several advantages:
- Asynchronous requests: Scrapy can send multiple requests simultaneously, making it much faster than other scraping tools.
- Built-in selectors: Scrapy provides powerful tools to extract data from websites using XPath and CSS selectors.
- Robustness: Scrapy automatically handles retries, redirects, and even some anti-scraping mechanisms like rate limiting.
- Extensibility: Its modular architecture allows you to easily extend its functionalities with middlewares, pipelines, and custom spiders.
- Community and documentation: Being open-source, Scrapy has a large and active community, and excellent documentation, making it easier for developers to get help when needed.
If you’re considering web scraping for business applications, Scrapy’s versatility will undoubtedly appeal to you.
How to Install Scrapy?
Before you start web scraping with Scrapy, you need to install it. Ensure that you have Python installed on your system, as Scrapy is a Python-based framework.
To install Scrapy, follow these simple steps:
- Open your terminal (or command prompt).
- Create a new virtual environment (optional but recommended to avoid conflicts):
bash
Copy code
python -m venv scrapyenv
Activate the environment:
- On Windows:
bash
Copy code
scrapyenvScriptsactivate
- On macOS/Linux:
bash
Copy code
source scrapyenv/bin/activate
- Install Scrapy using pip:
bash
Copy code
pip install scrapy
This will install Scrapy and its dependencies.
Once installed, you’re ready to start your Scrapy web scraping project!
Creating a Scrapy Web Scraping Project
After installing Scrapy, the next step is to create a project. Scrapy organizes each scraping task into its own project, which makes it easy to manage multiple scrapers.
- In your terminal, navigate to the directory where you want to create the project.
- Run the following command:
bash
Copy code
scrapy startproject myproject
- This will create a folder named myproject with the following structure:
markdown
Copy code
myproject/
scrapy.cfg
myproject/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.py
The spiders directory is where you will define your web crawlers (spiders), which are the heart of any Scrapy web scraping project.
Writing Your First Spider
A spider is a class that defines how to follow links and extract data from web pages. To start web scraping with Scrapy, we’ll write a simple spider.
- Navigate to the spiders folder:
bash
Copy code
cd myproject/spiders
- Create a new Python file for your spider (e.g., quotes_spider.py):
bash
Copy code
touch quotes_spider.py
In this file, we’ll define a simple spider that scrapes quotes from the website quotes.toscrape.com.
python
Copy code
import scrapy
class QuotesSpider(scrapy.Spider):
name = “quotes”
start_urls = [
‘http://quotes.toscrape.com’,
]
def parse(self, response):
for quote in response.css(‘div.quote’):
yield {
‘text’: quote.css(‘span.text::text’).get(),
‘author’: quote.css(‘span small::text’).get(),
‘tags’: quote.css(‘div.tags a.tag::text’).getall(),
}
next_page = response.css(‘li.next a::attr(href)’).get()
if next_page is not None:
yield response.follow(next_page, self.parse)
Breakdown of the Code:
- name: The name of the spider.
- start_urls: A list of URLs to start scraping from.
- parse(): The main method where we define the logic for extracting data. It uses CSS selectors to extract the quote, author, and tags from the webpage.
- The spider follows pagination using the next_page link.
Running the Spider
To run your spider, use the following command in your terminal:
bash
Copy code
scrapy crawl quotes
By default, Scrapy will print the scraped data to the console. If you want to save the output to a file, use:
bash
Copy code
scrapy crawl quotes -o quotes.json
This will save the data in JSON format, but you can also export it in CSV or XML.
Customizing Your Scrapy Web Scraping Spider
Now that you’ve built your first spider, let’s explore some ways to customize it for more complex scraping tasks:
1. Handling Pagination:
Scrapy handles pagination well, but for complex sites, you might need to customize the link-following logic. Use the response.follow() method for this.
2. Data Cleaning:
Scrapy pipelines allow you to clean and process data before saving it. You can define custom pipelines in the pipelines.py file to transform, filter, or validate data.
3. Requestṣ Headers and User-Agent:
Some websites block scrapers by checking the User-Agent string. You can set custom headers in the settings.py file:
python
Copy code
USER_AGENT = ‘my-scraper (http://example.com)’
4. Handling JavaScript:
Scrapy doesn’t natively handle JavaScript-rendered content. For sites relying on JavaScript, consider integrating Scrapy with a tool like Selenium or Splash to render the content before scraping.
Challenges and How to Overcome Them
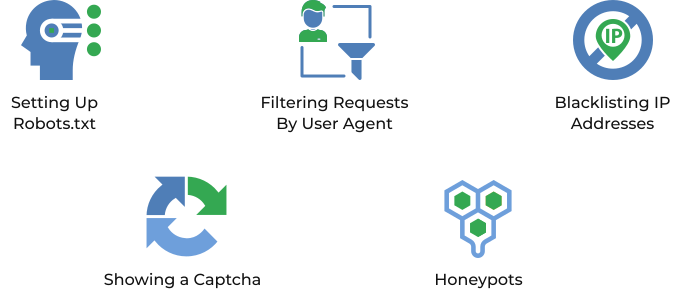
Image Source: Data-Ox
While Scrapy is powerful, there are some common challenges developers face when using it:
1. Anti-Scraping Measures:
Many websites implement anti-scraping techniques such as CAPTCHAs, IP blocking, or dynamic content loading. Solutions include:
- Rotating proxies and user agents.
- Using Scrapy’s AutoThrottle extension to adjust the crawl rate dynamically.
2. Dynamic Content:
As mentioned, Scrapy struggles with JavaScript-heavy websites. Combining it with headless browsers like Selenium or using APIs where available is often the best approach.
3. Handling Large Datasets:
Scraping large websites can result in huge datasets. Implementing efficient data storage methods like MongoDB, or streaming scraped data directly into a database, can make handling big data easier.
Managed Web Scraping Solutions
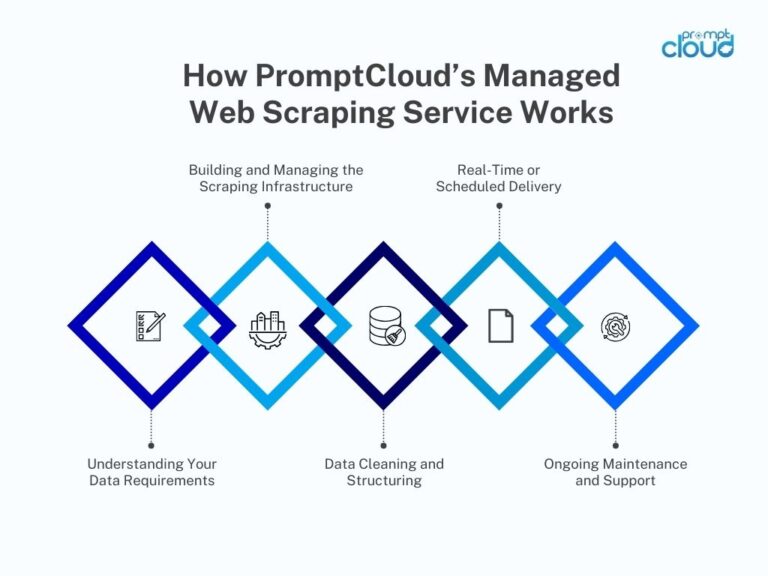
While web scraping with Scrapy offers unmatched flexibility for developers, managing large-scale scraping projects, handling dynamic content, and overcoming anti-scraping measures can be complex and time-consuming. If you’re a business looking to extract data but don’t want to deal with these challenges, a managed web scraping solution like PromptCloud can be a game-changer.
PromptCloud provides fully managed, scalable web scraping services tailored to your needs. Whether you need structured datasets from hundreds of websites or frequent updates, our scraping solutions help you focus on insights rather than infrastructure.
Conclusion
Scrapy web scraping is an excellent choice for developers who want a powerful, flexible, and scalable scraping framework. In this guide, we’ve covered how to install Scrapy, create a project, build a spider, and customize it for different use cases. While Scrapy is developer-friendly, businesses may prefer a fully managed solution to handle the complexities of large-scale scraping projects.
For those looking to extract data without the technical overhead, PromptCloud offers comprehensive, managed web scraping services. Schedule a demo today to discover how we can help you unlock the full potential of web data.















