



Table of Contents
show
Introduction to Inference Engines
There are many optimization techniques developed to mitigate the inefficiencies that occur in the different stages of the inference process. It is difficult to scale the inference at scale with vanilla transformer/ techniques. Inference engines wrap up the optimizations into one package and eases us in the inference process.
For a very small set of adhoc testing, or quick reference we can use the vanilla transformer code to do the inference.
The landscape of inference engines is quickly evolving, as we have multiple choices, it is important to test and short list the best of best for specific use cases. Below, are some inference engines experiments which we made and the reasons we found out why it worked for our case.
For our fine tuned Vicuna-7B model, we have tried
We went through the github page and its quick start guide to setup these engines, PowerInfer, LlaamaCPP, Ctranslate2 are not very flexible and do not support many optimization techniques like continuous batching, paged attention and held sub-par performance when compared to other mentioned engines.
To obtain higher throughput the inference engine/server should maximize the memory and compute capabilities and both client and server must work in a parallel/ asynchronous way of serving requests to keep the server always in work. As mentioned earlier, without help of optimization techniques like PagedAttention, Flash Attention, Continuous batching it will always lead to suboptimal performance.
TGI, vLLM and Aphrodite are more suitable candidates in this regard and by doing multiple experiments stated below, we found the optimal configuration to squeeze the maximum performance out of the inference. Techniques like Continuous batching and paged attention are enabled by default, speculative decoding needs to be enabled manually in the inference engine for the below tests.
Comparative Analysis of Inference Engines
TGI
To use TGI, we can go through the ‘Get Started’ section of the github page, here docker is the simplest way to configure and use the TGI engine.
Text-generation-launcher arguments -> this list down different settings we can use on the server side. Few important ones,
- –max-input-length: determines the maximum length of input to the model, this requires changes in most cases, as default is 1024.
- –max-total-tokens: max total tokens i.e input + output token length.
- –speculate, –quantiz, –max-concurrent-requests -> default is 128 only which is obviously less.
To start a local fine tuned model,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model –dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
To start a model from hub,
model=”lmsys/vicuna-7b-v1.5″; volume=$PWD/data; token=”<hf_token>”; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model –dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
You can ask chatGPT to explain the above command for more detailed understanding. Here we are starting the inference server at 9091 port. And we can use a client of any language to post a request to the server. Text Generation Inference API -> mentions all the endpoints and payload parameters for requesting.
E.g.
payload=”<prompt here>”
curl -XPOST “0.0.0.0:9091/generate” -H “Content-Type: application/json” -d “{“inputs”: $payload, “parameters”: {“max_new_tokens”: 400,”do_sample”:false,”best_of”: null,”repetition_penalty”: 1,”return_full_text”: false,”seed”: null,”stop_sequences”: null,”temperature”: 0.1,”top_k”: 100,”top_p”: 0.3,”truncate”: null,”typical_p”: null,”watermark”: false,”decoder_input_details”: false}}”
Few observations,
- Latency increases with max-token-tokens, which is obvious that, if we are processing long text, then overall time will increase.
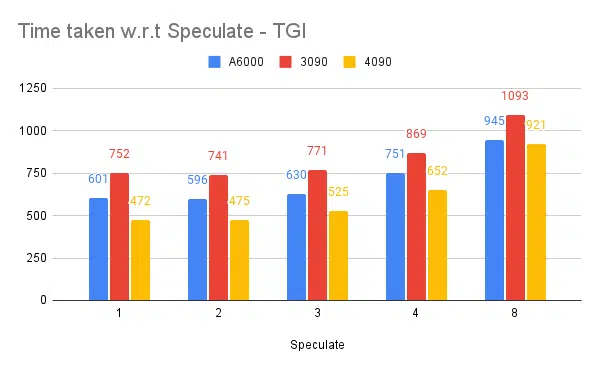
- Speculate helps but it depends on use-case and input-output distribution.
- Eetq quantization helps the most in increasing the throughput.
- If you have a multi GPU, running 1 API on each GPU and having these multi GPU APIs behind a load-balancer results in higher throughput than sharding by TGI itself.
vLLM
To start a vLLM server, we can use an OpenAI compatible REST API server/ docker. It is very simple to start, follow Deploying with Docker — vLLM, if you are going to use a local model, then attach the volume and use the path as model name,
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest –model /model
Above will start a vLLM server on the mentioned 8000 port, as always you can play with arguments.
Make post request with,
“`shell
payload=”<prompt here>”
curl -XPOST -m 1200 “0.0.0.0:8000/v1/completions” -H “Content-Type: application/json” -d “{“prompt”: $payload,”model”:”/model” ,”max_tokens”: 400,”top_p”: 0.3, “top_k”: 100, “temperature”: 0.1}”
“`
Aphrodite
“`shell
pip install aphrodite-engine
python -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
“`
Or
“`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc host alpindale/aphrodite-engine
“`
Aphrodite provides both pip and docker installation as mentioned in the getting started section. Docker is generally relatively easier to spin up and test. Usage options, server options help us how to make requests.
- Aphrodite and vLLM both uses, openAI server based payloads, so you can check its documentation.
- We tried deepspeed-mii, since it is in transitional state(when we tried) from legacy to new codebase, it does not look reliable and easy to use.
- Optimum-NVIDIA doesnt support major other optimizations and results in suboptimal performance, ref link.
- Added a gist, the code we used to do the ad hoc parallel requests.
Metrics and Measurements
We want to try out and find:
- Optimal no. of threads for the client/ inference engine server.
- How throughput grows w.r.t increase in memory
- How throughput grows w.r.t tensor cores.
- Effect of threads vs parallel requesting by client.
Very basic way to observe the utilization is to watch it via linux utils nvidia-smi, nvtop, this will tell us the memory occupied, compute utilization, data transfer rate etc.
Another way is to profile the process using GPU with nsys.
| S.No | GPU | vRAM Memory | Inference engine | Threads | Time (s) | Speculate |
| 1 | A6000 | 48 /48GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48 /48GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48 /48GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48 /48GB | TGI | 256 | 568 | – |
Based on above experiments, 128/ 256 thread is better than lower thread number and beyond 256 overhead starts contributing towards reduced throughput. This is found to be dependent on CPU and GPU, and needs one’s own experiment. | ||||||
| 5 | A6000 | 48 /48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48 /48GB | TGI | 128 | 945 | 8 |
Higher speculate value causing more rejections for our fine-tuned model and thus reducing throughput. 1 / 2 as speculate value is fine, this is subject to model and not guaranteed to work the same across use cases. But the conclusion is speculative decoding improves the throughput. | ||||||
| 7 | 3090 | 24/ 24GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/ 24GB | TGI | 128 | 481 | 2 |
4090 has even though less vRAM compared to A6000, it outperforms due to higher tensor core count and memory bandwidth speed. | ||||||
| 8 | A6000 | 24/ 48GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2 x 24/ 48GB | TGI | 128 | 1205 | 2 |
Setting Up and Configuring TGI for High Throughput
Set up asynchronous requesting in a scripting language of choice like python/ ruby and with using the same file for configuration we found:
- Time taken increases w.r.t maximum output length of sequence generating.
- 128/ 256 threads on client and server is better than 24, 64, 512. When using lower threads, the compute is being under-utilized and beyond a threshold like 128 the overhead becomes higher and thus throughput has reduced.
- There is a 6% improvement when jumping from asynchronous to parallel requests using ‘GNU parallel’ instead of threading in languages like Go, Python/ Ruby.
- 4090 has 12% higher throughput than A6000. 4090 has even though less vRAM compared to A6000, it outperforms due to higher tensor core count and memory bandwidth speed.
- Since A6000 has 48GB vRAM, to conclude whether the extra RAM helps in improving throughput or not, we tried using fractions of GPU memory in experiment 8 of the table, we see the extra RAM helps in improving but not linearly. Also when tried splitting i.e hosting 2 API on the same GPU with using half memory for each API, it behaves like 2 sequential API running, instead of accepting requests parallelly.
Observations and Metrics
Below are graphs for some experiments and the time taken to complete a fixed input set, lower the time taken is better.
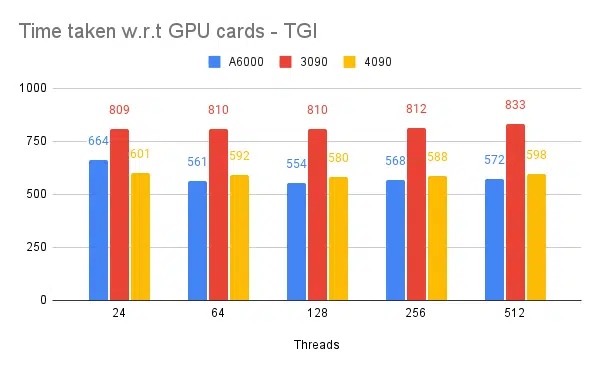
- Mentioned is client side threads. Server side we need to mention while starting the inference engine.
Speculate testing:
Multiple Inference Engines testing:
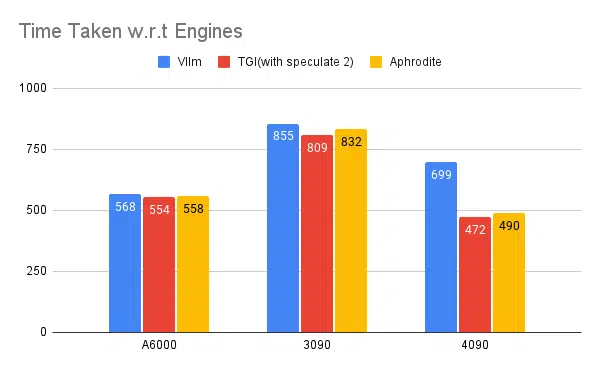
Same kind of experiments done with other engines like vLLM and Aphrodite we observe similar kind of results, as of when writing this article vLLM and Aphrodite doesn’t support speculative decoding yet, that leaves us to pick TGI as it gives higher throughput than rest due to speculative decoding.
Additionally, you can configure GPU profilers to enhance observability, aiding in the identification of areas with excessive resource usage and optimizing performance. Further read: Nvidia Nsight Developer Tools — Max Katz
Conclusion
We see the landscape of inference generation is constantly evolving and improving throughput in LLM requires a good understanding of GPU, performance metrics, optimization techniques, and challenges associated with text generation tasks. This helps in choosing the right tools for the job. By comprehending GPU internals and how they correspond to LLM inference, such as leveraging tensor cores and maximizing memory bandwidth, developers can choose the cost-efficient GPU and optimize performance effectively.
Different GPU cards offer varying capabilities, and understanding the differences is crucial for selecting the most suitable hardware for specific tasks. Techniques like continuous batching, paged attention, kernel fusion, and flash attention offer promising solutions to overcome arising challenges and improve efficiency. TGI looks the best choice for our use case based on the experiments and results we obtain.
Understanding GPU Architecture for LLM Inference Optimization













