


Table of Contents
show
Companies have always used data to stay on the top. When businesses worked out of brick and mortar stores, most of this data crunching was offline since the datasets were smaller. As more companies have moved their businesses online (or at least parts of it), datasets have grown in sizes and now reach sizes up to terabytes and petabytes. These datasets are made up of:
a). Internal data that may contain product details, employee information, partner contracts, warehouse-stock updates, and more
b). Data from IoT devices like GPS sensors, smart robots, tracking sensors, and digital twins
c). External data such as competitor data scraped from the web
The data from different sources may not all be in the same shape and format. You can have data in textual, audio, video, and even tabular format. Once you have converted all of them to a single structured format, you would spot that not all of them have the same headers. Even if they do, the units may not be the same. There may also be duplicate rows present in the data.
What is Data Normalisation?
The processing of all such data issues together adds up and is collectively called Data Normalisation. It mainly helps in data collated from different sources to be reorganized and used together. It also improves the readability of the data for the business team and thus provides a more plug and play approach to creating data visualizations.
Data Normalisation may comprise multiple stages where each stage may be further divided into different steps for different data sources. The most common data normalization techniques or stages involve:
a). Removal of duplicate entries
b). Grouping data based on logical grouping methodology
c). Creating associations between related data points
d). Resolving conflicting data entries
e). Converting different data-sets to a single format
f). Conversion of semi-structured or unstructured data to key-value sets
g). Consolidation of data from multiple sources
h). Conversion of all rows in a column to same units
i). Dividing columns with large numeric values by powers of 10
j). Assigning numerical values to categorical columns
Such efforts together lead to improving the quality of data in general and also help in reducing the processing required in business-workflows where these datasets eventually get used. Such processes can be used to handle different types of fields such as names, addresses, phone numbers, pin codes, currency values, the distance between two points, and more. Every company defines a set of standard formats and rules according to which all the data sets that enter the data-stream are normalized.
Raw Data can be processed in different ways based on the set of standardization rules in place. Some examples of data standardization are shown in the table below.
| Raw Data | Normalized Data |
| 25 south park | 25 South Park |
| Sr VP Ad | Senior Vice President of Advertisement |
| 1 centimeter | 1cm |
| 1 foot | 30.48cm |
| Male/Female/Others | M/F/O |
| $25 | ₹1850 |
What if you do not Normalise your Data?
Based on research conducted by Gartner, almost 40% of all business-efforts are lost due to poor data quality. Bad data or badly formatted data impact different stages in business processes and impair operational efficiency as well as risk management. When data-backed decisions are based on faulty data, the business’ ability to use data to its advantage is compromised. The benefits of using big data for business decisions are lost when you are unable to standardize and fit in different data sources.
One of the major enemies of usable data is missing or broken data – rows where not all the data points may be present correctly. Such issues may arise either due to incorrect processing of raw data or due to inconsistencies in the source data. The other major data-issue that renders data unusable is the amount of unstructured data that isn’t broken down into usable bits.
As per one study by Priceonomics, as much as 55% of data collected by companies go unused. This unused data that was collected by companies but could not be used due to certain constraints is termed as dark-data. When asked for the reasons behind not being able to use such a large fraction of the data, 66% of the respondents chose “missing or broken data” as the answer whereas 25% chose to complain about the unstructured formats.
As companies keep aggregating data from both internal and external sources, the net data size keeps increasing. Today most companies are using cloud storage services by services like AWS or GCP and it is easy to forget how large your infra bills are getting. While most services charge you based on the queries you perform and not the size of data stored, you will still need to take into account three things:
a). As the data volume grows, the queries will need to parse more and more data and will take longer to execute
b). As an effect of queries taking longer to execute, multiple queries running at the same time may lead to a timeout error
c). As the amount of data being parsed for every query increases, the costs incurred for cloud services would rise steadily
The Benefits of Data Normalisation
One of the biggest benefits of Data Normalization is the ability to implement Data Segmentation. Data Segmentation is the capability to group data based on different parameters so that they can be used more easily by different internal teams. Data can be segmented by different factors like the gender of customers, location (urban or rural), industry type, and more.
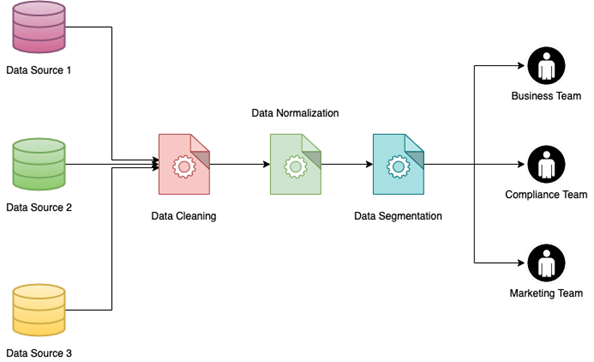
Implementing Data Segmentation on a large data set, especially one that has been compiled by joining multiple sources of data, can be a daunting task. It will be many times easier though if the data has already been normalized. The benefits of this are multi-pronged:
a). If data is normalized and segmented, different teams can pull out different data without worrying about the need for filtering unclean or broken data.
b). Companies can use a targeted advertising and marketing approach using segmented data to get better conversion rates in their limited marketing budgets.
c). Segmented data can also help companies in analyzing their results and customer feedback and understand what went right and what went downhill. This information can make or break a company based on whether it is consumed or left on the table.
Forecasting customer behavior and detecting anomalies are some of the main targets for large enterprises that analyze big volumes of data and try to create predictive models. Efforts behind such endeavors can be greatly minimized if the raw data itself has been stored after normalization and standardization. Whether your Data Science team is working on a new machine learning model or your business team is working to build a recommender system that would compare to Netflix’s, clean and normalized data is an absolute necessity as a starting point.
How Bad Can Things Get?
Data Normalisation can be helpful when multiple teams are using the same data source or communicating between themselves through data. The higher the number of data sources and the greater the number of teams and individuals involved, the higher the risks of non-normalized data. One of the major historical events that occurred to non-normalized data was that of the $125 million Mars Probe which was lost since engineers failed to convert values from the English to the Metric System. Unit conversions to maintain uniformity remains one of the core Data Normalization Techniques.
Your losses may not account for such a high value, but you may not be able to calculate the losses that occur due to cluttered data. It would slowly seep into one of the major reasons for data unusability. Indirectly, the percentage of unused data at your company would signify the loss due to not putting in the efforts to normalize data.
While we spoke a lot about normalization and standardization of data, fetching the data properly itself is half the work done. If you scrape data cleanly from external sources, your efforts for normalizations can be greatly reduced. Our team at PromptCloud prides itself in providing customers with a DaaS (Data as a Service) solution using which companies can just provide us with their web scraping requirements and we offer the data in a plug and play format. We can scrape data from multiple websites and provide data from each in different containers or via different APIs. Once this is done, you can then write your Data Normalisation modules to aggregate the data and enrich them – thus enabling your team to make data-backed decisions.













