



Table of Contents
show
In today’s AI-driven world, deep learning models have become the backbone of cutting-edge image recognition technology. From facial recognition to object detection and medical imaging, the ability to train deep learning models accurately determines their real-world effectiveness. But what fuels these powerful algorithms? The answer lies in data – vast quantities of high-quality, diverse data. And for acquiring such data at scale, web scraping emerges as a game-changing tool.
This article explores the integral role web scraping plays in training deep learning models for image recognition, highlighting its benefits, challenges, and best practices.
The Data Challenge in Training Deep Learning Models
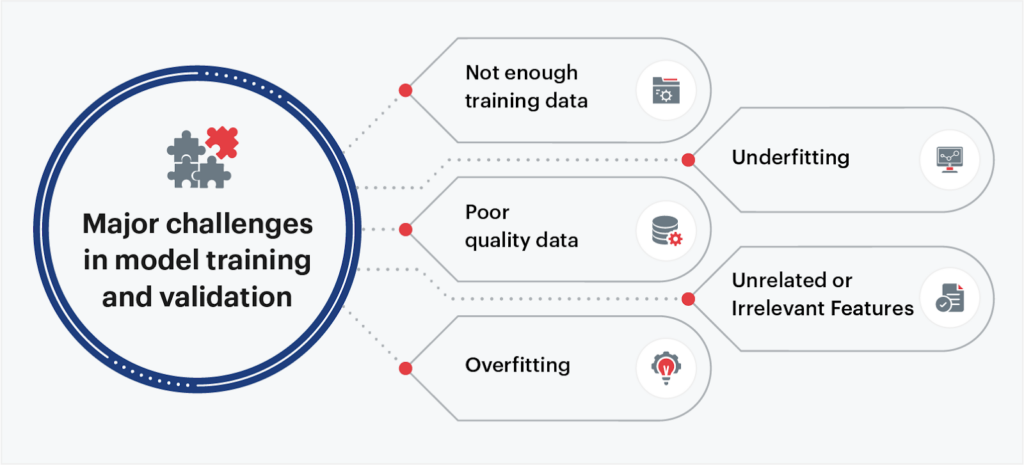
Source: sigmoid
To train a deep learning model, especially for image recognition, you need a large and diverse dataset. The more diverse and representative the dataset, the better the model can generalize to real-world scenarios. However, sourcing such data presents several challenges:
- Volume: Training state-of-the-art image recognition models requires thousands to millions of images.
- Diversity: Models must learn to recognize objects in various environments, angles, and lighting conditions.
- Labeling: For supervised learning, images must be annotated with accurate labels, adding complexity to the process.
These challenges make it clear that relying solely on pre-existing datasets or manual collection is insufficient. This is where web scraping comes into play.
What Is Web Scraping and How Does It Help?
Web scraping is the process of extracting data from websites using automated tools or scripts. For image recognition tasks, web scraping can be tailored to collect large volumes of images from diverse sources across the internet. This harvested data can then be used to train deep learning models effectively.
Here are a few ways web scraping supports image recognition:
- Scalability: It automates the data collection process, enabling the acquisition of millions of images in a fraction of the time manual methods would take.
- Diversity: Images can be sourced from various websites, covering different regions, contexts, and use cases.
- Customization: Scraping can target specific types of images, ensuring relevance to the problem domain.
Why Web Scraping is Essential for Deep Learning AI Training?
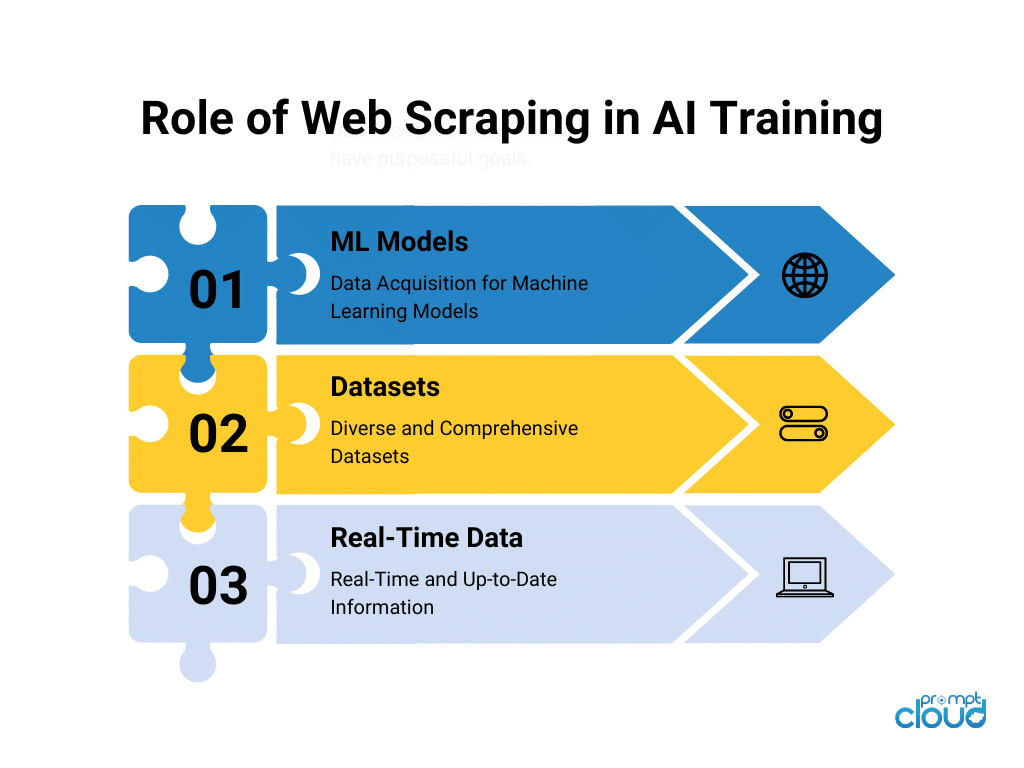
1. Access to Large-Scale Data
Deep learning thrives on data volume. The more data you have, the better your model’s performance. Web scraping enables access to virtually unlimited data from websites, ensuring your model has enough examples to learn effectively.
For instance:
- A facial recognition system might scrape images from social media profiles (within ethical boundaries).
- An object detection model for retail might scrape product images from e-commerce platforms.
2. Enhanced Diversity
Diversity in training data helps prevent overfitting and improves a model’s ability to generalize. By scraping data from multiple sources, you can train deep learning models to recognize objects in various contexts and environments.
3. Cost Efficiency
Purchasing datasets or manually collecting images can be prohibitively expensive. Web scraping offers a cost-effective alternative, reducing data acquisition costs significantly while providing ample flexibility.
4. Continuous Updates
The real world is constantly changing, and so should your training data. Web scraping allows for ongoing data collection, enabling you to retrain deep learning models with the latest, most relevant information.
How Web Scraping Works for Image Recognition?
To leverage web scraping for image recognition effectively, follow these steps:
- Define Objectives: Determine the type of images your deep learning model requires. For example, if you’re building an AI to identify wildlife, your targets might include animal images from nature photography websites.
- Select Sources: Identify websites with the desired image content. Examples include e-commerce platforms, photo-sharing sites, or domain-specific repositories.
- Develop a Scraper: Use tools like Python’s BeautifulSoup or Scrapy to build scripts that crawl websites and extract image URLs. Automation tools like Selenium are helpful for dynamic sites.
- Download and Organize: Scraped images need to be downloaded and organized into categories based on labels. Proper categorization ensures seamless integration into the training pipeline.
- Annotation: If labels are missing, use annotation tools or services to label the images accurately.
- Preprocessing: Images might need resizing, normalization, or augmentation to fit the model’s requirements.
Ethical Considerations in Training Deep Learning Models

1. Copyright and Usage Rights
Images on the internet are often protected by copyright. Ensure compliance with intellectual property laws by:
- Scraping only from sources that allow data collection.
- Using images for non-commercial research purposes.
- Seeking permission or licensing content where necessary.
2. Data Quality
Scraped data can be noisy, with irrelevant or low-quality images. Implement robust filtering mechanisms to ensure the dataset’s quality aligns with your objectives.
3. Legal Compliance
Web scraping is governed by laws like the General Data Protection Regulation (GDPR). Adhering to these regulations is critical to avoid legal repercussions.
4. Technical Challenges
Dynamic websites and anti-scraping measures like CAPTCHAs can complicate the process. Partnering with experienced web scraping providers can help overcome these hurdles.
Best Practices for Using Web Scraping to Train Deep Learning Models
- Use Ethical and Legal Methods: Always ensure that your scraping activities comply with legal and ethical guidelines.
- Leverage Advanced Scraping Tools: Tools like PromptCloud offer scalable, efficient, and compliant web scraping solutions tailored to your data needs.
- Focus on Data Diversity: Scrape from multiple sources to build a robust, diverse dataset.
- Regularly Update Your Dataset: Keep your model relevant by periodically updating the training data using fresh scraped images.
- Invest in Data Cleaning: Dedicate resources to filter and preprocess the scraped data for maximum utility.
How PromptCloud Simplifies Web Scraping for Deep Learning?
PromptCloud is a leader in providing customizable web scraping solutions. With advanced capabilities tailored to AI and machine learning needs, PromptCloud can:
- Scrape data from dynamic and complex websites.
- Deliver clean, structured datasets ready for training deep learning models.
- Ensure compliance with legal and ethical standards.
By partnering with PromptCloud, you can focus on training deep learning models while leaving the complexities of data acquisition to experts.
Conclusion
Web scraping has become an indispensable tool in training deep learning models for image recognition. By automating the process of data acquisition, it enables access to vast, diverse datasets essential for building accurate, robust AI systems. While challenges like copyright and data quality persist, best practices and ethical approaches can mitigate these risks.For businesses and researchers aiming to train deep learning models efficiently, web scraping offers an unparalleled advantage. And with a trusted partner like PromptCloud, you can unlock the full potential of web scraping, powering your AI models with the data they need to excel in real-world applications. For custom data for training AI models, get in touch with us at sales@promptcloud.com















