



Table of Contents
show
The rapid development of large language models (LLMs) like GPT-4, custom AI solutions, and Retrieval-Augmented Generation (RAG) systems has been one of the defining technological trends of recent years. Central to this progress is the need for high-quality, up-to-date data to train these models and fine-tune them for real-world applications. This has led to a surge in demand for web scraper—critical tool that extract publicly available information from websites at scale. In this article, we’ll explore why web scrapers are indispensable for training AI models, how they power real-time applications, and how PromptCloud provides the essential data solutions for these advanced technologies.
The Data Hunger of Large Language Models
Large Language Models (LLMs) like OpenAI’s GPT-3 and GPT-4 are powered by vast amounts of text data. Training these models requires not just quantity but also the diversity and richness of the datasets. In essence, these models are like sponges, absorbing information to predict the next word, complete sentences, or generate sophisticated responses based on user inputs.
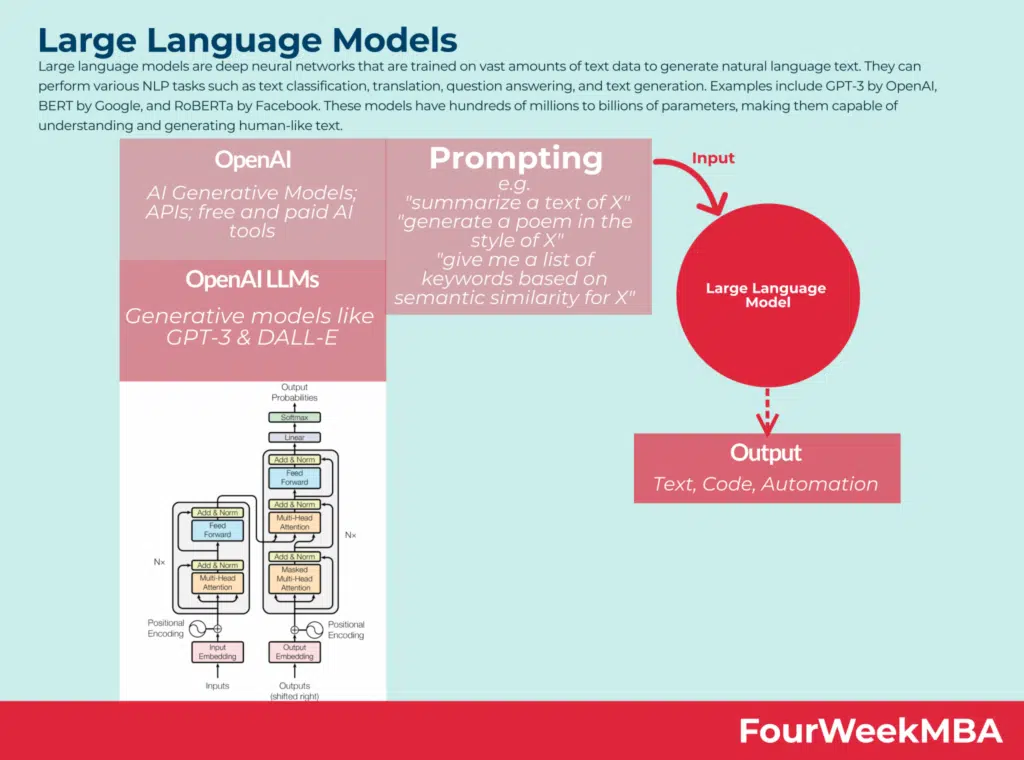
Image Source: FourWeekMBA
Why Data Diversity Matters?
A well-trained LLM needs exposure to a wide range of topics, dialects, writing styles, and domains to perform accurately across different contexts. Web scraping becomes indispensable here, as the web offers:
- Diverse Content Sources: Scraping helps gather data from blogs, academic journals, news websites, e-commerce platforms, and social media.
- Real-Time Updates: Data needs to be fresh, particularly for models that interact with real-time data feeds or deal with trending topics, product reviews, or breaking news.
- Language Variety: The web is a global resource, offering information in countless languages and dialects, making scraping essential for training multilingual models.
How Web Scraping Enhances Custom GPTs and RAG Technologies?
The rise of Custom GPTs (Generative Pre-trained Transformers tailored for specific use cases) and RAG (Retrieval-Augmented Generation) has further pushed the need for real-time, high-quality data. These models are tuned or trained for specific industries, businesses, or tasks, which means they need highly targeted data.
1. Real-Time Data for Custom GPTs
Custom GPTs are trained to specialize in particular industries or fields. For example, a financial institution might need a GPT specialized in analyzing stock market trends, or a legal firm may want one proficient in case law.
- Targeted Data Collection: Web scraping enables businesses to collect highly specific datasets that reflect the current trends and nuances of their industry.
- Dynamic Learning: Real-time scraping tools ensure that these models are not static, but can evolve with the latest data, improving decision-making and generating insights relevant to the moment.
2. RAG: Elevating Performance with Real-Time Knowledge
RAG systems combine the best of two worlds—retrieval-based models and generative AI. While LLMs are trained on static datasets, RAG systems can pull in real-time information from external sources to provide more accurate, up-to-date responses.
- Real-Time Data Retrieval: Web scraping enables RAG systems to fetch the latest information from external databases, web pages, or news outlets, offering more relevant and context-aware responses.
- Improved Accuracy: By supplementing the static knowledge of LLMs with real-time scraped data, RAG models can significantly improve accuracy, especially in fast-changing fields like finance, sports, or politics.
Why Web Scraping is Essential for AI Researchers & Data Scientists?
AI researchers and data scientists are constantly in search of rich, diverse, and large-scale datasets to train their models. While publicly available datasets like Wikipedia or Common Crawl are widely used, these often lack the domain-specific nuances that many advanced AI applications require.
1. The Limits of Public Datasets
Although large language models are often trained on datasets like Common Crawl, public datasets have their limitations:
- Generalization Issues: Public datasets may not cover niche domains with the depth and specificity needed for certain AI applications.
- Data Freshness: Static datasets do not reflect the real-time trends or updates that are critical in some industries.
- Lack of Industry-Specific Data: For example, training an AI to understand the medical domain requires highly specialized data, which is often scattered across different healthcare portals, journals, and forums.
2. The Role of Web Scraping
Web scraping provides a solution to these challenges by enabling AI researchers and data scientists to access:
- Niche-Specific Data: Scraping allows researchers to extract information from specialized sources—whether it’s scientific papers, financial reports, or product reviews—providing the granularity needed for highly customized models.
- Up-to-Date Information: Web scraping ensures that the data used to train or fine-tune models is always current, enhancing the relevance and applicability of AI outputs.
- Scalable Solutions: With the right web scraper tool, vast amounts of data can be collected and processed, offering the scalability required for training large models.
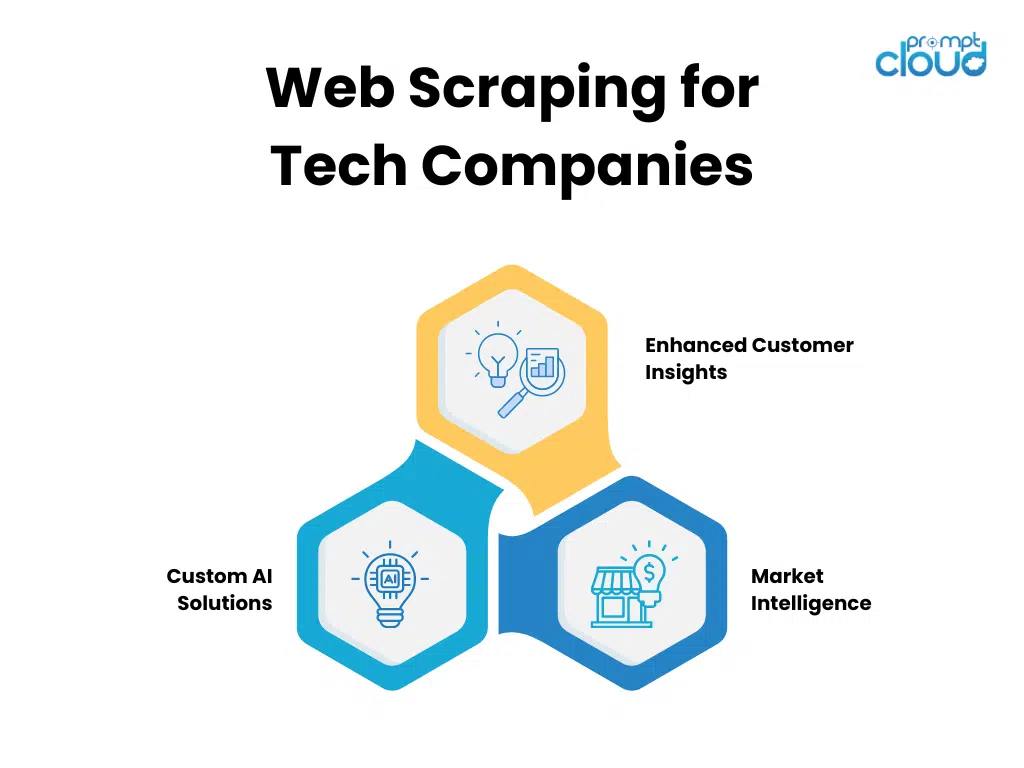
3. Web Scraping for Tech Companies
Tech companies building AI products, such as chatbots, recommendation engines, and decision-support systems, rely on real-time data for optimal performance. From product development to customer support, having access to the latest, most relevant information is key to staying ahead in a competitive market.
Key Benefits of Web Scraping for Tech Companies:
- Enhanced Customer Insights: E-commerce platforms use scraping to gather product reviews, competitive pricing information, and consumer sentiment from forums and social media, which can feed into AI-powered recommendation engines.
- Market Intelligence: Companies in fintech or healthcare can use web scraping to collect market data or health trends, which can be fed into predictive models that drive better business decisions.
- Custom AI Solutions: Tech companies often build AI models that require domain-specific data. Web scraping allows for the extraction of the precise information needed to create custom AI solutions tailored to specific industries or use cases.
Why PromptCloud’s Web Scraper is Essential for Data-Driven AI Projects?
While web scraping is a powerful tool, it requires the right technology and expertise to gather, process, and deliver data efficiently. This is where PromptCloud steps in, offering a robust, scalable web scraping solution that meets the demands of AI researchers, data scientists, and tech companies alike.
Why Choose PromptCloud?
- Custom Data Solutions: Whether you need general web scraping services or highly customized data feeds for a specific use case, PromptCloud offers tailored solutions that meet your unique requirements.
- Scalability: Our online web scraper is designed to handle large-scale data collection, ensuring that your AI models can be trained with vast amounts of high-quality, relevant data.
- Real-Time Data: For applications that require up-to-the-minute information, our platform offers real-time scraping capabilities, ensuring that your AI systems are always equipped with the latest data.
- Diverse Data Sources: With the ability to scrape data from a wide variety of sources—ranging from blogs to academic journals—PromptCloud ensures that your AI models are trained on a rich and diverse dataset.
- Data Quality: Our web scraper tool is built to ensure that the data gathered is clean, structured, and ready for use, saving you time and resources on data preprocessing.
The Best Web Scraper for Custom AI Solutions
PromptCloud’s scraping platform stands out as one of the best web scraper solutions available for AI development. Whether you’re building a custom GPT, training a RAG model, or fine-tuning a large language model for a specific use case, our web scraper tool delivers the high-quality, real-time data that your AI systems need.
Here’s how PromptCloud helps:
- Ease of Use: Our platform is easy to integrate with your existing data pipeline, ensuring a smooth, hassle-free process for collecting and processing data.
- Customizability: We understand that every AI project has unique data requirements, and our flexible platform allows you to specify exactly what you need.
- Cost-Efficiency: By using a web scraper tool that delivers high-quality, structured data directly to your models, you can save on data acquisition costs while boosting the performance of your AI systems.
Web Scraping’s Growing Role in AI Development
As AI technologies continue to evolve, the demand for real-time, high-quality data will only increase. Future developments in LLMs, Custom GPTs, and RAG systems will likely rely even more on web scraping, especially as models become more specialized and domain-specific.
- The Rise of Domain-Specific AI Models
As businesses continue to seek out AI solutions that are finely tuned to their industry’s needs, domain-specific AI models will become increasingly popular. These models will require not only static datasets but also real-time, relevant information from niche sources—a need that only web scraping can fulfill.
- Real-Time AI Decision Making
In fast-paced industries like finance, healthcare, and e-commerce, real-time decision-making powered by AI will become the norm. These systems will rely on online web scrapers to feed them continuous streams of updated data, ensuring that their predictions and recommendations are always accurate and timely.
Conclusion
Web scraping is no longer just a tool for data extraction; it has become an essential part of the AI development pipeline. From training LLMs to building custom GPTs and RAG models, web scraping provides the real-time, domain-specific data that is critical for today’s advanced AI applications.
PromptCloud offers a scalable, efficient, and customizable web scraper tool that helps businesses, researchers, and data scientists access the high-quality data they need for their AI projects. Whether you’re working on the next breakthrough in AI or building custom models for industry-specific applications, PromptCloud’s web scraping solutions provide the competitive edge you need to stay ahead.In a world driven by data, PromptCloud ensures that your AI systems are always learning from the best sources available. Contact us today to find out how we can help your AI project thrive in a data-hungry world.














