




Web Data Scraping and Big Data Analytics
Web data scraping has emerged as a pivotal mechanism for harvesting online data. This process involves the automated retrieval of information from websites, transforming the unstructured web into a wealth of structured data ripe for analysis.
Image Source: https://www.sas.com/
Concurrently, big data analytics has carved a niche in discerning patterns, trends, and insights from the massive datasets accumulated, often through web data scraping. As vast volumes of data (approx. 2.5 quintillion bytes of data being generated each day) become more accessible, the synthesis of web data scraping with big data analytics unlocks a myriad of possibilities for businesses, researchers, and policymakers.
By skillfully combining these technological capabilities, they position themselves to capitalize on data-guided decision-making, spur service innovations, and mold strategic undertakings tailored to their objectives. Nevertheless, it’s essential to acknowledge the surfacing of ethical dilemmas resulting from the synergistic relationship between these advanced tools.
A fine line must be carefully tread regarding the crucial balance between maximizing data value and preserving individuals’ privacy rights, ensuring neither aspect overshadows the other.
Web Data Scraping Benefits of for Big Data Projects
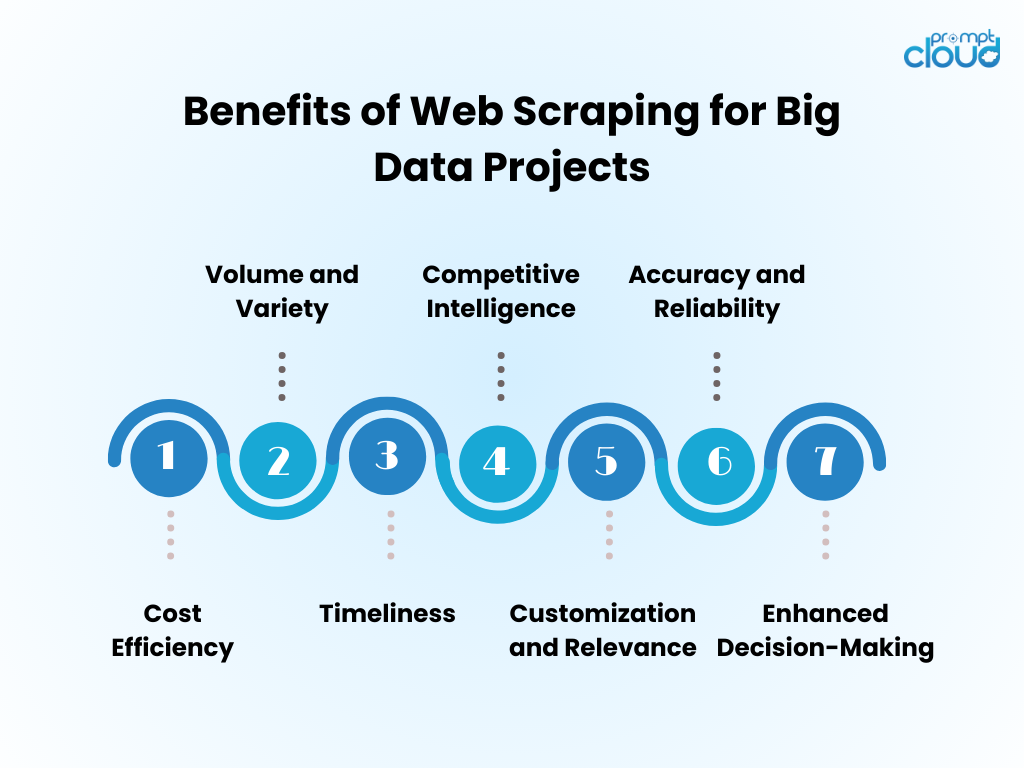
- Cost Efficiency: Automating data collection through web scraping significantly reduces human labor costs and accelerates time-to-insight.
- Volume and Variety: It enables the capture of vast amounts of data from diverse sources, critical for feeding big data analytics.
- Timeliness: Web scraping provides real-time or near-real-time data, allowing for more agile responses to market trends.
- Competitive Intelligence: It empowers organizations with the ability to monitor competitors and industry changes closely.
- Customization and Relevance: Data can be tailored to specific needs, ensuring that analysis is relevant and focused.
- Accuracy and Reliability: Automated scraping minimizes human error, leading to more accurate data sets.
- Enhanced Decision-Making: Access to timely, relevant data supports informed decision-making and strategic planning.
Web Scraping Techniques: From Basic to Advanced
Web data scraping has evolved with technology, beginning with basic techniques that advance as data complexity grows.
- Basic Techniques: Initially, scrapers retrieve data using simple HTTP requests to obtain HTML pages, parsing the content through libraries like Beautiful Soup in Python. These tools can adequately handle uncomplicated websites.
- Intermediate Techniques: For dynamic content, techniques evolve to include automation tools like Selenium, which can interact with JavaScript and mimic browser behavior.
- Advanced Techniques: Moving towards advanced scraping, methods incorporate headless browsers, and proxy servers to navigate around anti-scraping measures. Data extraction becomes sophisticated with machine learning algorithms, processing natural language and images to retrieve information.
- Ethical Considerations: Regardless of technique complexity, ethical dilemmas persist, necessitating a balance between data access and respect for privacy and ownership.
Incorporating Web-Scraped Data into Big Data Analytics
Web-scraped data, when integrated into big data analytics, can unveil comprehensive market insights and consumer trends. Analysts meld web-scraped information with existing datasets, enhancing the depth and breadth of analytical outcomes. This amalgamation begets improved predictive models, tailored marketing strategies, and refined consumer profiles.
- Data Cleaning: Scraped data requires meticulous cleansing to ensure accuracy in analytics.
- Data Integration: Combining scraped data with other sources necessitates advanced data integration techniques.
- Analysis Enhancement: With additional data, machine learning algorithms can reveal more nuanced patterns.
- Ethical Consideration: Analysts must ensure web data usage complies with legal and ethical standards.
The augmented data pool drives innovation, yet demands rigorous methodology and ethical oversight.
Best Practices for Efficient Web Scraping
- Respect robots.txt protocols; do not scrape sites that disallow it via their robots file.
- Schedule scraping activities during off-peak times to minimize impact on the target server’s performance.
- Utilize caching to avoid re-scraping the same content, respecting the website’s data and saving bandwidth.
- Implement appropriate error handling to prevent your scraper from crashing and to avoid sending too many requests in case of errors.
- Rotate user agents and IP addresses to prevent being blocked, simulating more natural browsing behavior.
- Stay informed about legal and ethical web scraping practices, ensuring your scraping activities are not violating copyrights or privacy laws.
- Optimize code to be efficient and reduce load on both the scraping system and the target websites.
- Regularly update the scraping code to adapt to any changes in website layout or technology, maintaining the efficacy and accuracy of your data retrieval.
- Store collected data securely and manage it in compliance with all relevant data protection regulations.
Future of Web Scraping in the Era of Big Data
As Big Data continues to expand, web data scraping is poised to become even more integral to data analysis and business intelligence. The future will likely see:
- Enhanced machine learning models trained with vast datasets obtained through scraping, improving accuracy and insights.
- Increased demand for real-time data scraping, allowing businesses to make quicker, data-driven decisions.
- Development of more sophisticated scraping tools to navigate anti-scraping technologies and maintain ethical data gathering practices.
- Stricter regulations and privacy laws shaping web data scraping methodologies, ensuring that data is collected responsibly and with consent.
- The emergence of scraping-as-a-service platforms, offering tailored data extraction for businesses of all sizes.
With these advancements, web scraping will continue to be a critical tool in the Big Data toolkit.
Should manual web scraping feel daunting or if assistance is required to untangle intricate challenges related to obtaining valuable data, rest assured that PromptCloud stands ready to help!
We specialize in delivering comprehensive web scraping solutions designed explicitly for big data initiatives, ensuring dependable, large-scale data extraction.
Trust us to tackle the demanding aspects, enabling you to concentrate on generating well-informed choices utilizing robust and meaningful datasets. Get in touch with us at sales@promptcloud.com to discover how our expertise can boost your big data game plan!















