


Table of Contents
show
In the Big Data world, Web Scraping or Data extraction services are the primary requisites for Big Data Analytics. Pulling up data from the web has become almost inevitable for companies to stay in business. Next question that comes up is how to go about web scraping as a beginner.
Web scraping refers to the process of retrieving information from websites for various purposes. It involves the automated crawling of web pages and retrieving relevant information, such as text, images, videos, and other multimedia content. Python is a popular programming language for web scraping due to its simplicity, flexibility, extensive library support, and easy-to-use syntax. In this article, we will discuss the basics of web scraping using Python.
Before we dive into Python libraries, let’s understand the basics of web scraping. Web scraping involves the following steps:
- Sending HTTP requests to the website to retrieve HTML content
- Parsing the HTML content to extract the desired data
- Storing the data in a structured format
Popular Python Libraries
Image Source: https://www.projectpro.io/
Now let’s look at some of the popular Python libraries used for web scraping:
BeautifulSoup –
This library is used for parsing HTML and XML documents. It provides a simple interface to navigate, search, and modify the parse tree. Beautiful Soup can handle a variety of HTML and XML documents and is commonly used for web scraping.
Requests –
This library is used for making HTTP requests in Python. It simplifies sending HTTP requests and managing the corresponding responses. Requests can be used to retrieve HTML content from web pages, which can then be parsed using Beautiful Soup.
Selenium –
This library is used for automating web browsers. It can be used for web scraping when the website uses JavaScript to render content. It can locate HTML elements and extract their contents, making it useful for scraping dynamic web pages.
Web Scraping Using Python
Now that we have covered the basics, below are the steps for web scraping using Python:

Image Source: https://medium.datadriveninvestor.com/
- Choose a website: Identify the website from which you want to scrape data.
- Inspect the website: Use your browser’s developer tools to inspect the website’s structure and identify the HTML tags that contain the data you want to scrape.
- Install the necessary libraries: The most common libraries used in web scraping with Python are BeautifulSoup and Requests. Use pip to install them:
- Retrieve the website content: Use the requests library to send an HTTP request to the website and retrieve the HTML content.
- Parse the HTML: Use BeautifulSoup to parse the HTML content and extract the data.
- Store the data: Store the extracted data in a data structure such as a CSV file, database, or JSON file.
Best Practices for Web Scraping Using Python
Here are some pointers to keep in mind when you are web scraping using Python:
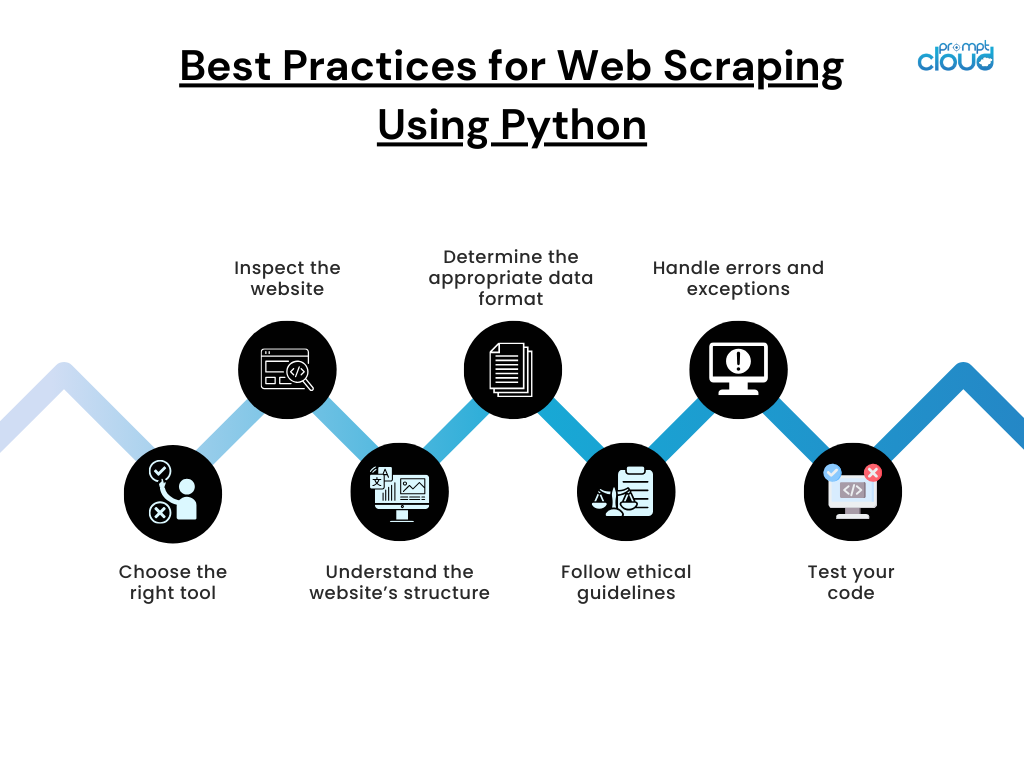
Choose the right tool:
Select the appropriate tool or library for the job. Popular web scraping libraries in Python include BeautifulSoup, Scrapy, and Selenium.
Inspect the website:
Use your browser’s developer tools to inspect the website’s structure and identify the relevant HTML tags and attributes.
Understand the website’s structure:
Learn about the website’s layout and how it organizes its content. This can help you to better identify and extract the information you need.
Determine the appropriate data format:
Decide on the appropriate format for the extracted data, such as CSV, JSON, or a database.
Follow ethical guidelines:
Be aware of the ethical considerations around web scraping and follow guidelines and legal requirements. Respect the website’s terms of use, and avoid scraping data that is copyrighted or restricted.
Handle errors and exceptions:
Ensure that your code can handle unexpected errors or exceptions. For example, if a website’s structure changes, your code may need to be updated to reflect the changes.
Test your code:
Before deploying your web scraper, test your code thoroughly to ensure that it is working correctly and efficiently. Over time, this could potentially result in significant savings of both time and resources.
Setting up a Python Environment:
To carry out web scraping using Python, you will first have to install the Python Environment, which enables you to run code written in the python language. The libraries perform data scraping;
Beautiful Soup is a convenient-to-use python library. It is one of the finest tools for extracting information from a webpage. Professionals can crawl information from web pages in the form of tables, lists, or paragraphs. Urllib2 is another library that can be used in combination with the BeautifulSoup library for fetching the web pages. Filters can be added to extract specific information from web pages. Urllib2 is a Python module that can fetch URLs.
For MAC OSX :
To install Python libraries on MAC OSX, users need to open a terminal win and type in the following commands, single command at a time:
sudoeasy_install pip
pip install BeautifulSoup4
pip install lxml
For Windows 7 & 8 users:
Ensure that Windows 7 & 8 users install the Python environment first. After installing the environment, open the command prompt, navigate to the root C:/ directory, and enter the following commands:
easy_install BeautifulSoup4
easy_installlxml
Once you install the libraries, it’s time to write a data scraping code.
Running Python:
You must perform data scraping for a specific objective, such as crawling the current stock of a retail store. First, use a web browser to navigate the website containing this data. After identifying the table, right-click anywhere on it and then select the inspect element from the dropdown menu list. This will cause a window to pop-up on the bottom or side of your screen displaying the website’s Html code. The rankings appear in a table. You might need to scan through the HTML data until you find the line of code that highlights the table on the webpage.
Python offers some other alternatives for HTML scraping apart from BeautifulSoup. They include:
- Scrapy
- Scrapemark
- Mechanize
Web scraping converts unstructured data from HTML code into structured data form such as tabular data in an Excel worksheet. One can perform web scraping using various methods, ranging from the use of Google Docs to programming languages. For people who do not have any programming knowledge or technical competencies, it is possible to acquire web data by using web scraping services that provide ready to use data from websites of your preference.
HTML Tags:
To perform web scraping, users must have a sound knowledge of HTML tags. It might help a lot to know that HTML links are defined using anchor tag i.e. <a> tag, “<a href=“https://…”>The link needs to be here </a>”. An HTML list comprises <ul> (unordered) and <ol> (ordered) list. The item of list starts with <li>.
HTML tables are defined with<Table>, row as <tr> and columns are divided into data as <td>;
- <!DOCTYPE html> : A HTML document starts with a document type declaration
- The main part of the HTML document in unformatted, plain text is defined by <body> and </body> tags
- The headings in HTML are defined using the heading tags from <h1> to <h5>
- Paragraphs are defined with the <p> tag in HTML
- An entire HTML document is contained between <html> and </html>
Using BeautifulSoup in Scraping:
While scraping a webpage using BeautifulSoup, the main concern is to identify the final objective. For instance, if you want to extract a list from a webpage, you need to follow a step-by-step approach:
-
First and foremost step is to import the required libraries:
#import the library used to query a website
import urllib2
#specify the url wiki = “https://”
#Query the website and return the html to the variable ‘page’
page = urllib2.urlopen(wiki)
#import the Beautiful soup functions to parse the data returned from the website
from bs4 import BeautifulSoup
#Parse the html in the ‘page’ variable, and store it in Beautiful Soup format
soup = BeautifulSoup(page)
-
Use function “prettify” to visualize nested structure of HTML page
-
Soup<tag> is used for returning content between opening and closing tag including tag.
- In[30]:soup.title
Out[30]:<title>List of Presidents in India till 2010 – Wikipedia, the free encyclopedia</title>
- soup.<tag>.string: Return string within given tag
- In [38]:soup.title.string
- Out[38]:u ‘List of Presidents in India and Brazil till 2010 in India – Wikipedia, the free encyclopedia’
- Find all the links within page’s <a> tags: Tag a link using tag “<a>”. So, go with option soup.a and it should return the links available in the web page. Let’s do it.
- In [40]:soup.a
Out[40]:<a id=”top”></a>
-
Find the right table:
Identifying the right table is important when searching for a table to pull up information about Presidents in India and Brazil till 2010. Here’s a command to crawl information enclosed in all table tags.
all_tables= soup.find_all(‘table’)
Identify the right table by using the attribute “class” of the table that needs to filter the right table. Thereafter, inspect the class name by right-clicking on the required table of the web page as follows:
- Inspect element
- Copy the class name or find the class name of the right table from the last command’s output.
right_table=soup.find(‘table’, class_=’wikitable sortable plainrowheaders’)
right_table
That’s how we can identify the right table.
-
Extract the information to DataFrame:
There is a need to iterate through each row (tr) and then assign each element of tr (td) to a variable and add it to a list. Let’s analyze the Table’s HTML structure of the table. (extract information for table heading <th>)
To access the value of each element, there is a need to use the “find(text=True)” option with each element. Finally, there is data in dataframe.
There are various other ways to crawl data using “BeautifulSoup” that reduce manual efforts to collect data from web pages. Code written in BeautifulSoup is considered to be more robust than the regular expressions. The web scraping method we discussed use “BeautifulSoup” and “urllib2” libraries in Python. That was a brief beginner’s guide to start using Python for web scraping.
Stay tuned for our next article on how web scraping affects your revenue growth.
Planning to acquire data from the web for data science? We’re here to help. Let us know about your requirements.















