



Table of Contents
show
Introduction to Web Scraping with Python
Web scraping is a strategic technology used to extract data from websites. This process automates the retrieval of information from web pages, transforming unstructured data into structured data that businesses can utilize for a multitude of strategic operations. Given the exponential growth of data generation and the competitive edge that data-driven decision-making offers, web scraping with Python is now integral to operational and strategic frameworks across various industries.
Python is the preferred programming language for developing custom web scraping solutions due to its robust features and supportive ecosystem. Here’s why Python is particularly advantageous for business applications:

Source: redswitches
- Ease of Use and Readability: Python’s straightforward syntax ensures that scripts are easy to write and maintain, which is vital for businesses looking to adapt quickly to market changes.
- Comprehensive Libraries: Python offers specialized libraries such as BeautifulSoup, Scrapy, and Selenium. These tools simplify tasks related to data retrieval, HTML parsing, and browser automation, significantly reducing development time.
- Scalability: Python’s flexibility supports the development of both simple scripts for small-scale data needs and complex systems for large-scale corporate data processing.
- Strong Community Support: The extensive Python developer community is an invaluable resource for troubleshooting, updates, and continuous learning, ensuring that business solutions stay current and effective.
Setting Up Python Environment
Getting started with Python for web scraping requires a properly configured environment. Here’s how you can set up your system to ensure everything runs smoothly for your web scraping with Python projects.
Installing Python
First, you need to install Python. It’s recommended to download the latest version of Python 3 from the official Python website. This version includes all the latest features and improvements. You can verify the installation by opening your command prompt or terminal and typing python –version. This command should display the version number, confirming that Python is ready to use.
Creating a Virtual Environment
It’s best practice to use a virtual environment for your Python projects. This isolates your project’s libraries from the global Python installation and prevents conflicts between project dependencies. To create a virtual environment, navigate to your project directory in the terminal and run:
python -m venv env
Here, env is the name of the virtual environment folder; you can name it anything you like. To activate the virtual environment, use the following command:
On Windows:
envScriptsactivate
On macOS and Linux:
source env/bin/activate
Installing Packages
With your environment set up and activated, you can install the Python packages needed for web scraping. The most commonly used packages are requests for making HTTP requests and BeautifulSoup for parsing HTML and XML documents. Install these packages by running:
pip install requests beautifulsoup4
This command fetches the latest versions of requests and BeautifulSoup and installs them in your virtual environment.
Verifying Python Installation
To ensure that your installation is successful and the packages are correctly installed, you can import them in a Python shell. Just type python in your command line to open the shell, then enter:
import requests
import bs4 # bs4 is the package name for BeautifulSoup
If there are no errors, the packages are installed correctly, and you’re all set to start web scraping with Python!
This setup provides a robust foundation for any web scraping with Python project, allowing you to work with Python effectively and manage your project dependencies cleanly.
Basics of HTML & CSS Selectors
Web pages are built using HTML (HyperText Markup Language), which structures content through the use of elements and tags. These elements are the building blocks of any webpage, encompassing everything from headings and paragraphs to links and images. For anyone delving into web scraping with Python, a fundamental understanding of HTML is indispensable as it forms the basis of how you’ll locate and extract the data you need.
HTML Structure
An HTML document is structured as a tree of elements, starting with the <html> tag, followed by the <head> and <body> sections. The <head> contains metadata and links to scripts and stylesheets, while the <body> houses the actual content displayed on the webpage. Elements within the <body> are defined using tags like <p> for paragraphs, <a> for hyperlinks, <table> for tables, and many others. Each element can also have attributes like class, id, and style, which provide additional information about the element or change its appearance and behavior.
CSS Selectors
Source: atatus
CSS (Cascading Style Sheets) selectors are patterns used to select the elements you want to style or manipulate. When scraping web data, CSS selectors enable you to target specific elements from which you wish to extract information. There are several types of CSS selectors:
- Type selectors target elements by tag name. For example, p selects all <p> elements.
- Class selectors use the class attribute of an element for selection. For instance, .menu selects all elements with class=”menu”.
- ID selectors target elements based on the id attribute. For example, #header selects the element with id=”header”.
- Attribute selectors look for elements based on the presence or value of a given attribute. E.g., [href] selects all elements with an href attribute.
Using HTML and Style Selectors for Scraping
To efficiently scrape data from a web page, you need to inspect the page and understand its structure. This is typically done using the Developer Tools in web browsers like Chrome or Firefox. Here, you can view the HTML and identify which elements contain the data you want to scrape. Once identified, you can use CSS selectors to pinpoint these elements.
For instance, if you’re interested in scraping a list of news headlines from a webpage, you might find that each headline is wrapped in an <h1> tag within a div element that has a class of “news-item”. The CSS selector for this could be div.news-item h1, which selects all <h1> elements that are children of <div> elements with a class of “news-item”.
Creating your First Python Scraping Script
Writing a Python script to scrape data from a webpage can seem daunting at first, but by breaking down the process into manageable steps, you can start scraping data in no time. Here’s a simple guide to creating your first Python scraping script using the requests and BeautifulSoup libraries.
Step 1: Install Required Libraries
Before you start, make sure you have Python installed on your system. Then, you’ll need to install two Python libraries: requests for fetching the webpage and BeautifulSoup for parsing the HTML content. Install these libraries using pip:
pip install requests beautifulsoup4
Step 2: Import Libraries
Start your script by importing the necessary libraries. Create a new Python file and write the following code at the top:
import requests
from bs4 import BeautifulSoup
Step 3: Fetch the Webpage
Choose the URL of the webpage you want to scrape. Use the requests.get() function to fetch the page. This function retrieves the webpage and stores the response in a variable:
url = ‘http://example.com’ # Replace with the actual URL
response = requests.get(url)
Step 4: Parse the HTML Content
Once you have the webpage, you need to parse the HTML content. Use BeautifulSoup to parse the response.content and create a BeautifulSoup object:
soup = BeautifulSoup(response.content, ‘html.parser’)
Step 5: Extract Data
Decide what data you want to extract. For example, if you want to scrape all the headings (contained within <h1> tags) from the webpage, you can use the find_all() method from BeautifulSoup:
headings = soup.find_all(‘h1’)
for heading in headings:
print(heading.text.strip())
This code snippet will find all <h1> tags, loop through them, and print the text inside each tag.
Step 6: Handle the Data
Once you’ve extracted the data, you might want to store it in a file or a database, or perhaps clean it up for analysis. For simplicity, let’s write the headings to a text file:
with open(‘headings.txt’, ‘w’) as file:
for heading in headings:
file.write(f”{heading.text.strip()}n”)
Step 7: Run Your Script
Save your script and run it from your command line:
python your_script_name.py
Replace your_script_name.py with the name of your Python file. Check the output to ensure your script is working correctly.
This basic script can be expanded and modified to scrape different types of data from various websites. As you become more comfortable, you can start exploring more advanced web scraping with Python techniques and tools.
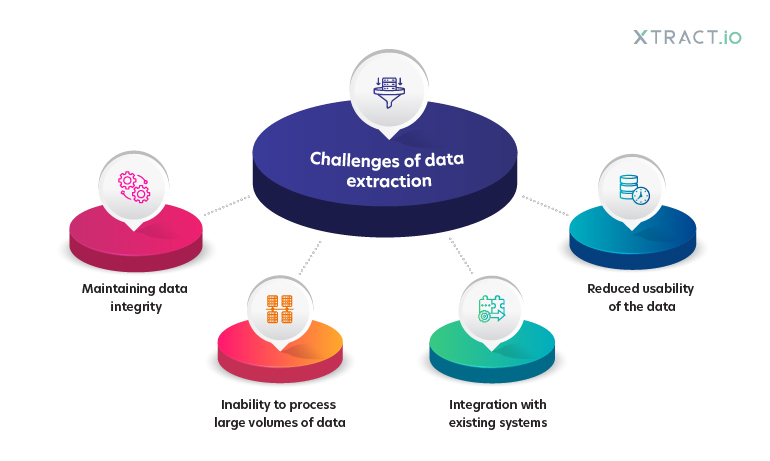
Overcoming Common Data Extraction Challenges
Source: xtract
Data extraction via web scraping can present numerous challenges, especially when dealing with complex website structures or dynamic content. Understanding these challenges and knowing how to address them is crucial for effective data collection. Here are some common issues you might encounter and strategies to overcome them:
- Dealing with Pagination
Many websites use pagination to organize large sets of data across multiple pages, which can complicate data extraction processes.
Solution: To handle pagination, you’ll need to automate the process of accessing each page and extracting the required data. This often involves identifying the URL pattern that the website uses for pagination and incorporating a loop in your script to iterate through all pages. For instance, if the URLs change by a simple query parameter (e.g., page=1, page=2), you can construct these URLs dynamically in your script:
base_url = ‘http://example.com/items?page=’
for i in range(1, number_of_pages + 1):
url = f”{base_url}{i}”
response = requests.get(url)
# Parse and extract data as previously described
- Scraping Dynamic Content
Some websites load their content dynamically using JavaScript, which means the data you need might not be present in the HTML returned by a simple HTTP request.
Solution:For websites that rely heavily on JavaScript, tools like Selenium or Puppeteer, which can automate a real browser, are often necessary. These tools can interact with the webpage as a user would (clicking buttons, scrolling, etc.) and can scrape data that is loaded dynamically:
from selenium import webdriver
driver = webdriver.Chrome() # or webdriver.Firefox(), etc.
driver.get(‘http://example.com/dynamic_content’)
# Code to interact with the page goes here
data = driver.find_element_by_id(‘data’).text
print(data)
driver.quit()
- Handling Rate Limiting and IP Bans
Websites may implement rate limiting or block your IP if you send too many requests in a short period.
Solution:To avoid getting banned or rate-limited, you should:
- Make requests at a slower rate. Implement delays or sleep intervals in your scraping loop.
- Rotate IP addresses and user agents. Using proxies and changing user agents can help mimic different users and reduce the risk of being blocked.
import time
import random
for url in urls:
time.sleep(random.randint(1, 5)) # Random sleep to mimic human behavior
response = requests.get(url, headers={‘User-Agent’: ‘Your User Agent String’})
# Parse response
Storing and Managing Scraped Data
Once you’ve successfully scraped data from the web, the next critical step is to store and manage it effectively. Proper data storage not only ensures that your data remains organized and accessible but also enhances the scalability of your data processing workflows. Here are some tips and best practices for storing and managing the data you’ve scraped:
Choosing the Right Storage Format
The format in which you store your scraped data can significantly impact how you use it later. Common formats include:
- CSV (Comma-Separated Values): Ideal for tabular data with a simple structure. It’s widely supported and easy to import into spreadsheet software or databases.
- JSON (JavaScript Object Notation): Best for hierarchical or nested data. JSON is highly favored in web applications and can be directly used in JavaScript environments.
- XML (eXtensible Markup Language): Useful for data with a complex structure or when you need a self-descriptive format that supports metadata.
Using Databases for Large-Scale Data
For more extensive or complex data collections, databases are more suitable due to their scalability and advanced query capabilities:
- Relational Databases (e.g., MySQL, PostgreSQL): Excellent for structured data that fits well into tables and rows. SQL databases support complex queries and are ideal for data integrity and transactional operations.
- NoSQL Databases (e.g., MongoDB, Cassandra): Better suited for unstructured or semi-structured data, or when the data schema may evolve over time. These are highly scalable and designed for high performance across large datasets.
Data Integrity and Validation
Ensuring the accuracy and completeness of your scraped data is crucial:
- Implement checks during the scraping process to validate data formats (e.g., dates, numbers).
- Regularly update your data scraping scripts to adapt to changes in the source website’s layout or schema.
Efficient Data Management Practices
Managing large datasets effectively is key to maintaining performance:
- Regular Backups: Schedule regular backups of your data to prevent data loss.
- Data Indexing: Use indexing in your databases to speed up query times and improve access patterns.
- Batch Processing: For large-scale data manipulation or analysis, consider using batch processing frameworks like Apache Hadoop or Spark.
Automating Data Updates
Web data can change frequently, so setting up automated scripts to update your data at regular intervals is beneficial:
- Use cron jobs (on Linux) or Task Scheduler (on Windows) to run your scraping scripts periodically.
- Monitor the health and performance of your scraping operations to catch and resolve errors promptly.
Security Considerations
Keep security in mind when storing sensitive or personal data:
- Comply with data protection regulations (e.g., GDPR, CCPA) to ensure you handle data lawfully.
- Encrypt sensitive data both in transit and at rest.
Example of Storing Data in CSV using Python:
- Here’s a simple example of how to save scraped data into a CSV file using Python:
import csv
data = [{‘name’: ‘Product A’, ‘price’: ’10’}, {‘name’: ‘Product B’, ‘price’: ’20’}]
keys = data[0].keys()
with open(‘products.csv’, ‘w’, newline=”) as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(data)
In Conclusion
With the foundations of effective web scraping, data storage, and management now in your toolkit, you are well-equipped to turn raw data into valuable insights. The journey from acquiring data to transforming it into actionable intelligence is pivotal in driving your business decisions and strategic initiatives.Ready to elevate your business with customized data solutions? Contact PromptCloud today to explore how our tailored data scraping services can empower your projects. Dive deeper into the world of data-driven decision-making and start transforming your approach to data today.













