



Table of Contents
show
Web scraping has become an indispensable tool for data collection in the digital age, enabling businesses to gather valuable insights from vast amounts of online data. One of the most powerful and flexible frameworks for web scraping is Scrapy. This open-source Python framework simplifies the process of extracting data from websites, making it an essential tool for developers and data enthusiasts alike. In this guide, we’ll explore how to leverage Scrapy for web scraping, from installation to advanced techniques, ensuring you can efficiently and effectively collect the data you need.
What is Scrapy?
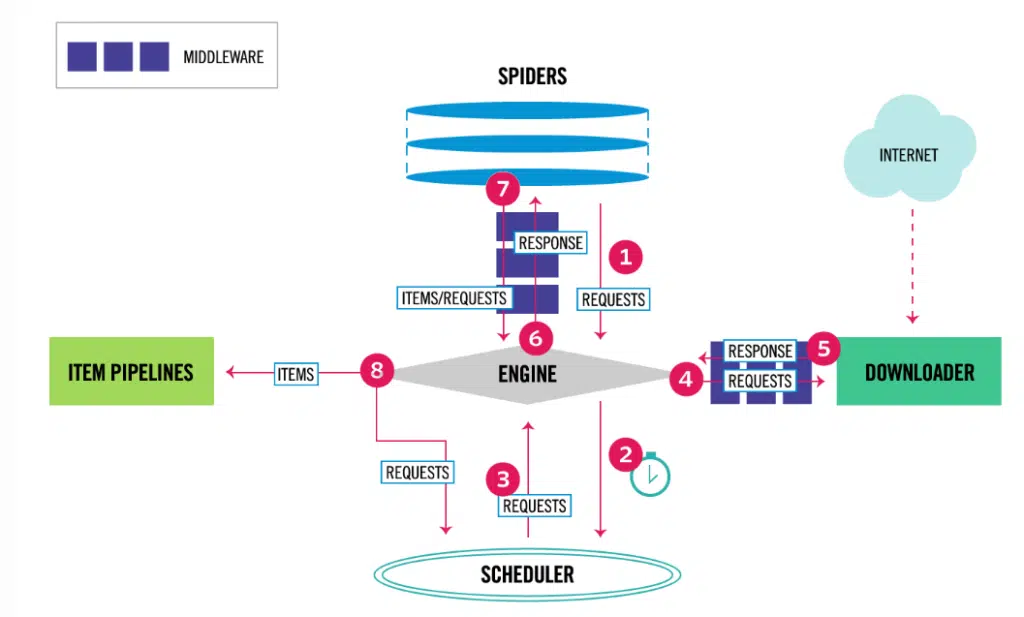
Image: Scrapy Architecture
Scrapy is a robust, open-source web scraping framework for Python, designed to extract data from websites quickly and efficiently. It provides a set of tools and libraries that simplify the web scraping process, making it accessible even for beginners.
Scrapy allows developers to define custom spiders, which are classes that specify how to navigate and extract data from websites. With its powerful selectors, Scrapy can parse HTML and XML documents, making it easy to extract the data you need. Built on the Twisted framework, Scrapy supports asynchronous network calls, enabling it to handle multiple requests simultaneously, which significantly speeds up the scraping process.
Additionally, Scrapy’s architecture is highly extensible, allowing developers to customize its behavior through middleware and pipelines. Middleware can process requests and responses globally, while pipelines can post-process the scraped data, such as cleaning, validating, and storing it in various formats like JSON, CSV, or databases.
Scrapy also includes robust error handling and logging mechanisms, ensuring that your scraping tasks run smoothly even when encountering issues like network errors or website changes. The Scrapy shell, an interactive tool for testing and debugging, further enhances the development experience by allowing you to test your extraction logic in real time.
How to Use Scrapy?
Using this tool involves several steps to set up, configure, and execute your scrapy web scraping projects efficiently. Here’s a detailed guide to help you get started:
Install Scrapy
First, ensure you have Python installed. Then, install Scrapy using pip:
pip install scrapy
For more detailed installation instructions, refer to the official Scrapy documentation.
Create a Scrapy Project
Start by creating a new Scrapy project. This sets up the necessary directory structure:
scrapy startproject myproject
cd myproject
This command creates a folder with the essential files for your project.
Define Your Spider
Spiders are the core of Scrapy, responsible for defining how to scrape a website. Create a new spider in the spiders directory:
import scrapy
class MySpider(scrapy.Spider):
name = “myspider”
start_urls = [‘http://example.com’]
def parse(self, response):
title = response.xpath(‘//title/text()’).get()
yield {‘title’: title}
This example spider starts at http://example.com and extracts the page title.
Run Your Spider
Execute your spider using the following command
scrapy crawl myspider
This initiates the crawling and scraping process.
Handle Requests & Responses
Scrapy allows you to manage requests and responses effectively. Use start_requests to initialize requests and parse to handle the responses:
def parse(self, response):
for href in response.css(‘a::attr(href)’).getall():
yield response.follow(href, self.parse_page)
def parse_page(self, response):
title = response.css(‘title::text’).get()
yield {‘title’: title}
This example follows links and extracts data from multiple pages.
Use Scrapy Shell
The Scrapy shell is a powerful tool for testing XPath and CSS selectors. Launch it with:
scrapy shell ‘http://example.com’
Test your extraction logic interactively:
response.xpath(‘//title/text()’).get()
response.css(‘title::text’).get()
Store Scraped Data
You can store scraped data in various formats like JSON, CSV, or XML:
scrapy crawl myspider -o output.json
Extend Scrapy
Scrapy provides middleware and pipelines to extend its functionality. Middleware processes requests and responses, while pipelines handle post-processing:
# In settings.py
DOWNLOADER_MIDDLEWARES = {
‘myproject.middlewares.MyCustomDownloaderMiddleware’: 543,
}
ITEM_PIPELINES = {
‘myproject.pipelines.MyCustomPipeline’: 300,
}
What are the Limitations of Scrapy?
While Scrapy is a powerful and flexible web scraping framework, it has some limitations that users should be aware of:
- JavaScript Handling:
- Scrapy struggles with websites that heavily rely on JavaScript for rendering content. It doesn’t execute JavaScript, which means it can miss data that is dynamically loaded.
- Complex Captchas:
- Scrapy can’t easily bypass advanced CAPTCHAs or other sophisticated anti-scraping mechanisms, requiring additional tools or manual intervention.
- Browser Emulation:
- Scrapy doesn’t provide built-in browser emulation, which can be necessary for scraping highly interactive websites. For such cases, integrating with tools like Selenium may be required.
- Learning Curve:
- Despite its powerful features, Scrapy has a steep learning curve, especially for beginners who are not familiar with Python or web scraping concepts.
- Resource Intensive:
- Large-scale scraping projects can be resource-intensive, requiring careful management of memory and processing power to avoid bottlenecks.
- Middleware Complexity:
- Customizing middleware and pipelines for specific needs can become complex, requiring a good understanding of Scrapy’s architecture and Python programming.
Understanding these limitations helps users plan their scraping projects better and decide when to use Scrapy or complement it with other tools for optimal results.
In Summary
Scrapy is a powerful framework that offers a wide range of functionalities for web scraping. It is particularly effective for projects that involve static content and structured data extraction. However, understanding its limitations is crucial for maximizing its utility and ensuring your scraping tasks are successful.
For businesses seeking more robust and scalable web scraping solutions, PromptCloud offers advanced web scraping services. With capabilities to handle dynamic content, bypass anti-scraping measures, and deliver high-quality data, PromptCloud can elevate your data extraction projects to new heights.
Discover how PromptCloud can transform your data strategy today. Schedule a demo today.



































